Your AI Vendor Claims Their LLM Can Reason. Here's What's Actually Happening.

President, Zaruko
Table of Contents
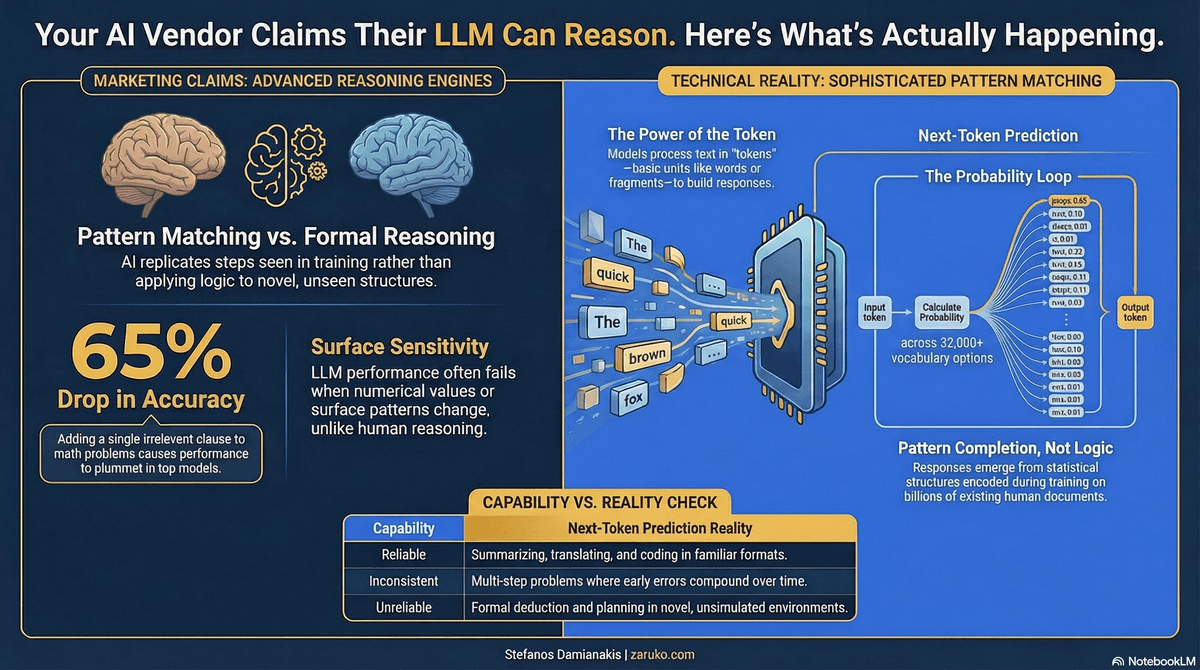
Most major AI vendors now market their latest models as capable of reasoning. OpenAI markets o1 and o3 as reasoning models. Google calls Gemini's capabilities "advanced reasoning." Anthropic describes Claude as capable of "complex reasoning and analysis." These claims appear in every product announcement, every investor deck, and every enterprise sales call.
Before you make decisions based on those claims, you need to understand one thing: every one of these models is doing the same thing at its foundation. It is predicting the next token.
That is not a simplification. It is the mechanism.
What a Token Is, and What the Model Actually Does
A token is a chunk of text, often a word or part of a word. Exact tokenization varies by model and architecture, but a sentence typically breaks into a handful of tokens, with longer or rarer words often split into pieces.
When you type a question into an AI model and press send, here is what happens. The model processes the tokenized input context and computes probabilities for the next token. For each position, it calculates a probability distribution over its entire vocabulary, which typically contains 32,000 to 100,000 possible tokens. It selects one token from that distribution. That token becomes the first word of the response. The model then repeats the process, now including that first output token as additional context, to produce the second token. Then the third. Then the fourth. This continues until the model produces a stop signal indicating the response is complete.
At the foundation, the model is still trained and run to predict the next token. There is no separate, guaranteed formal reasoning engine underneath. Any apparent reasoning has to emerge from that mechanism plus whatever external scaffolding surrounds it: tool use, intermediate steps, verification loops, or search.
This is not a criticism of LLMs. It is a description of what they are. The question is what that description implies about the capabilities vendors are claiming.
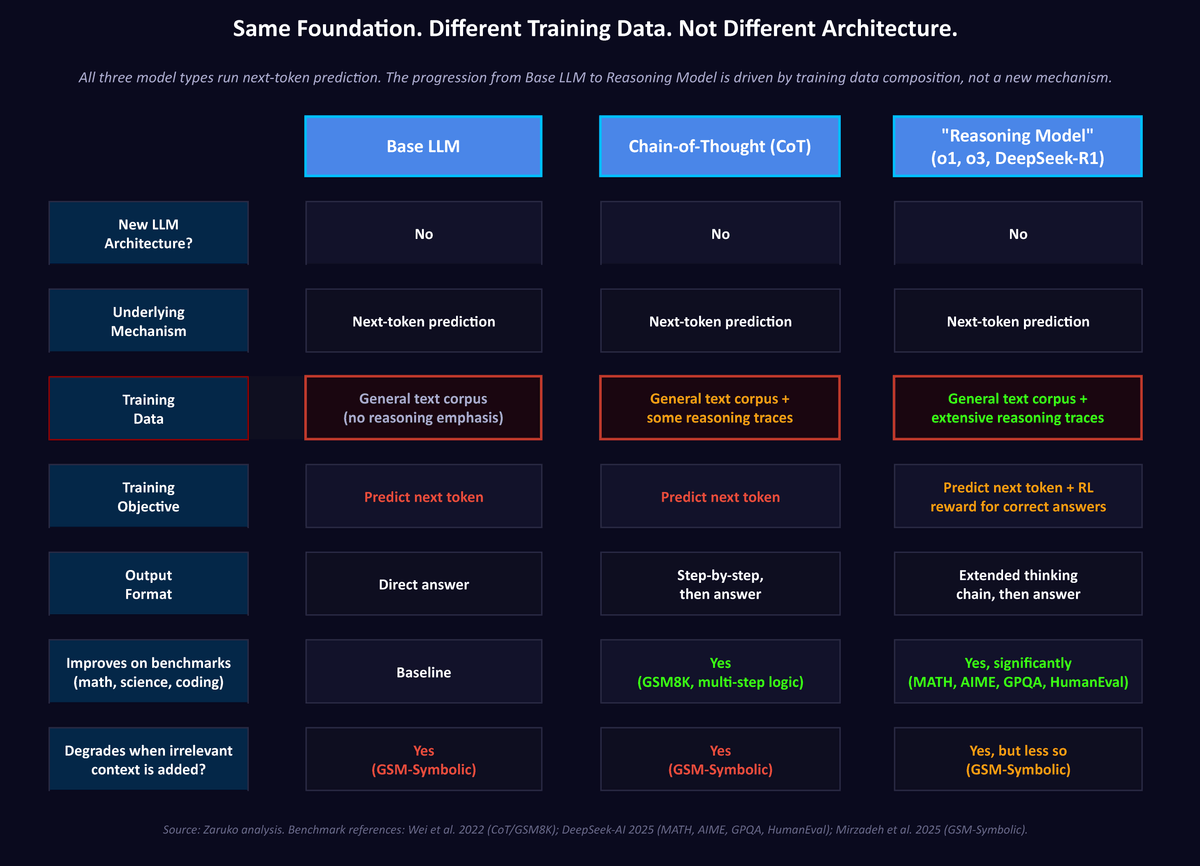
Figure 1: All three model types share the same core autoregressive mechanism. Reasoning models behave differently because the base next-token architecture is supplemented by different training, fine-tuning, and inference-time scaffolding, not because the core mechanism changed. Source: Zaruko analysis; Wei et al. 20222; DeepSeek-AI 20253; Mirzadeh et al. 20251.
Where the Impressive Results Come From
If the model is just predicting the next token, why does it produce outputs that look so capable?
The answer is in the training data and its scale. A large language model is trained on vast quantities of text: books, articles, code, scientific papers, legal documents, forum discussions, and much of the public internet. The exact scale varies by model and is often undisclosed, but the volumes involved are enormous. During training, the model adjusts billions of internal parameters to get better at predicting which token comes next in that corpus. After enough training, those parameters encode an enormous amount of statistical structure about how human knowledge is organized and expressed.
When you ask a well-trained model to explain a concept, it produces a response that resembles a good explanation because good explanations appear frequently in the training data and the model has learned the patterns that make them recognizable. When you ask it to write code, it produces code that looks correct because it has been trained on enormous volumes of code and documentation, reinforcing common and well-established coding patterns. When you ask it to solve a math problem, it produces text that follows the pattern of math problem solutions it has seen thousands of times.
This is real and useful. The patterns the model has learned are sophisticated enough to be valuable across an enormous range of tasks. The confusion arises when those patterns are mistaken for something they are not.
What the Model Actually Knows
This is the point most vendor marketing glosses over entirely.
These models are trained on language, not grounded experience. Whatever internal abstractions they develop are derived primarily from text, not from lived interaction with the physical world. That distinction matters more than almost anything else when evaluating what an LLM can and cannot do.
A language model has no model of the physical world. It does not know that objects fall, that collisions transfer force, that heat dissipates, that a structure under stress behaves differently than one that is not. It has no understanding of movement, momentum, or spatial relationships from experience. It has no grasp of action and reaction in the physical sense, not as a gap in its knowledge base, but as a fundamental consequence of what it is. A child who has dropped a glass understands something about gravity and fragility that no language model does, regardless of how many physics textbooks that model was trained on. Reading about gravity is not the same as having a model of how gravity works. The same is true of every physical phenomenon: collisions, fluid dynamics, structural failure, biological processes, the behavior of machines under load.
The same applies to every domain grounded in physical or causal reality. The model has no factory floor, no supply chain, no negotiating table, no balance sheet. It has text about those things. It has no understanding of action and reaction, no accumulated experience of what happens when decisions play out in the real world, no grounding in the consequences of being wrong.
A human who understands supply chains has seen them operate, noticed where they break, made decisions under uncertainty, and observed the consequences. A language model has processed text in which supply chains are discussed. Those are not the same thing. One is a model of the world. The other is a model of how people write about the world.
This has a direct practical consequence. When you ask an LLM for advice on a real business problem, it is not drawing on an understanding of how your industry works, how organizations behave, or how physical systems operate. It is pattern-matching against language that resembles your problem. If that language is well-represented in training data, the output can be remarkably useful. If it is not, or if your situation differs from the surface patterns the model has seen, the output can be confidently wrong in ways that are hard to detect.
This is not a criticism of what LLMs are. It is a description of what they are. The confusion comes from conflating fluency with understanding. A model that produces a fluent, well-structured analysis of a logistics problem has not understood the logistics problem. It has produced text that resembles analyses of logistics problems it has seen before.
What "Reasoning" Actually Requires
If by reasoning we mean formal, rule-based application under surface variation, the ability to apply logic to situations you have not seen before and arrive at correct conclusions regardless of how the problem is framed, then that is a high standard that current systems do not consistently meet.
A human who understands arithmetic can solve "47 plus 28" and also solve "47 plus 28, and by the way John has a dog." The irrelevant information about the dog does not change the answer. The human reasons about the structure of the problem, not its surface.
Apple's AI research team published a study in 2024 called GSM-Symbolic that tested whether language models could do this.1 They took a standard set of grade-school math problems and made minor changes: swapping names, altering numbers, adding an irrelevant sentence that had nothing to do with the solution. The finding was direct. All models showed significant performance drops when numerical values were changed. Adding a single irrelevant clause caused accuracy to fall by up to 65 percent across models that were considered among the best available. Apple's researchers concluded that the results are better explained by sophisticated pattern matching than by formal reasoning, and that models appear to replicate reasoning steps seen in training rather than applying logic to novel structures.
Note the separation: the dog analogy above is an illustration of the principle. The Apple experiment involved adding an irrelevant clause to math problems, not a dog sentence specifically. The result was the same: performance fell sharply because the surface patterns shifted, not because the logic changed. That is pattern completion, not reasoning.
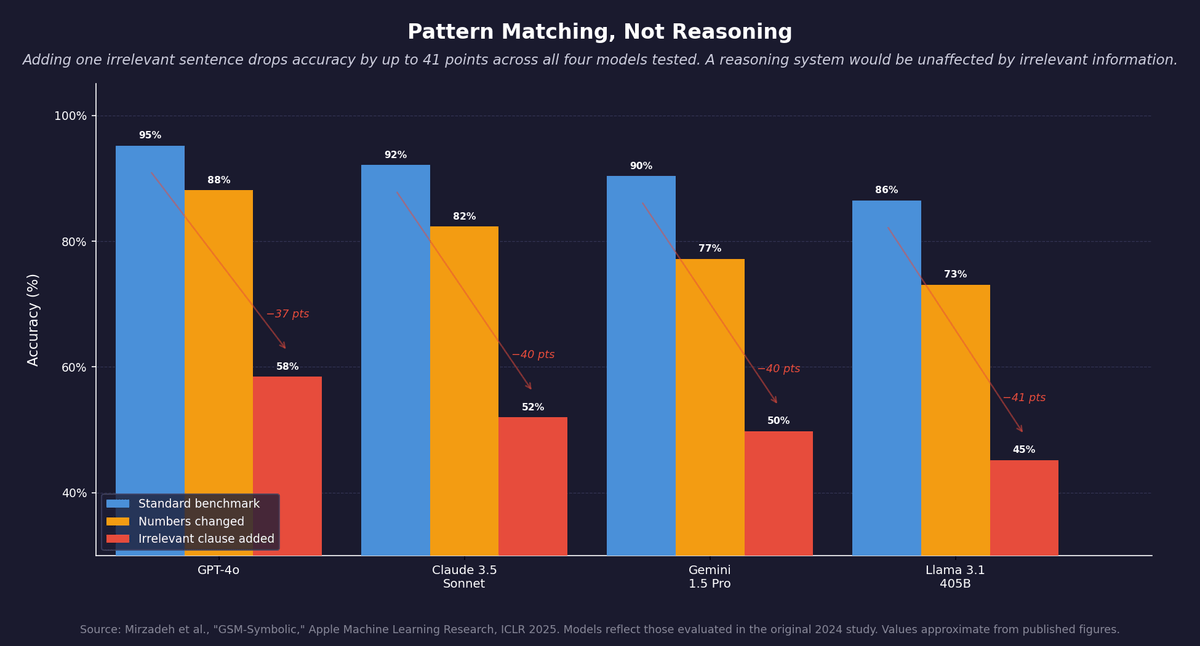
Figure 2: Apple's GSM-Symbolic study. Performance drops significantly when numbers are changed and collapses when an irrelevant sentence is added. Reasoning would be unaffected by irrelevant information. Source: Mirzadeh et al., ICLR 2025. Values approximate.
Why This Matters for Every Capability Claim
Understanding that LLMs predict tokens through pattern matching does not mean they are useless. They are extraordinarily useful for many things. But it does change how you should evaluate every capability claim you hear.
When a vendor says their model can reason, what they typically mean is one or more of three things. First, the model performs well on reasoning benchmarks. Benchmarks measure performance on specific test sets, and performance on a test set is not the same as general reasoning ability. A model that has seen similar problems in training will score well on a benchmark. That tells you something useful but limited.
Second, the model produces outputs that look like reasoning. Chain-of-thought prompting, a technique developed at Google in 2022, prompts the model to produce intermediate steps before giving a final answer.2 This reliably improves accuracy on complex problems. One likely reason it helps is that intermediate steps create more context for the model to build on, improving the final answer. Chain-of-thought often improves performance, but better performance does not by itself prove formal reasoning that holds under surface variation.
Third, the model has been fine-tuned to improve performance on tasks that look like reasoning. This includes the reasoning models now sold by major vendors. That fine-tuning is real and the performance improvements are real. But the underlying mechanism has not changed. Fine-tuning shapes which patterns the model applies to which inputs. It does not install a reasoning engine.
Three Things Next-Token Prediction Can and Cannot Do
This is the practical part.
What it does well: Generating fluent, accurate text in formats and domains well-represented in training data. Translating between languages. Summarizing documents. Writing and debugging code where the patterns are clear. Answering factual questions covered extensively in training. Following instructions where the desired output is a recognizable pattern. Explaining concepts. Drafting communications.
What it does inconsistently: Multi-step problems where early errors compound. Tasks that require tracking the state of a complex system across many steps. Problems that require applying rules correctly when surface patterns are unfamiliar. Arithmetic and formal logic under conditions that differ from training examples.
What it cannot do reliably: Formal deduction that holds regardless of irrelevant surface changes. Systematic reasoning that generalizes across novel structures it has not encountered before. Planning a sequence of actions in an environment it cannot simulate. Verifying its own outputs with certainty.
The boundary between these categories matters for every deployment decision you make. A model that performs well on a benchmark does not necessarily perform well when your specific business context changes the surface patterns it is used to.
Why Vendors Use the Word "Reasoning"
The word "reasoning" does a specific job in a sales conversation. It signals that the model can handle complex, high-stakes problems. It implies reliability and trustworthiness. It suggests that the model is doing something more than retrieval and recombination.
None of those implications are necessarily false in the domains where the model has been trained. In many contexts, the output is so good that the distinction between sophisticated pattern matching and reasoning does not matter practically.
But the distinction does matter when you are deciding how much autonomy to give an AI system, how much verification to require before acting on its outputs, and whether to deploy it in situations where the patterns it has learned are unlikely to cover what you encounter.
The next post in this series, Your AI Model Isn't Reasoning. It's Searching., looks at a specific example: a new benchmark from Oxford that tested whether AI could make progress on unsolved mathematical problems. The results were striking. And the way they were reported illustrates exactly the pattern described in this post.
Sources
- Mirzadeh et al., "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models," Apple Machine Learning Research, ICLR 2025. ↑
- Jason Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," Google Brain, NeurIPS 2022. ↑
- DeepSeek-AI, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning," January 2025. ↑
Frequently Asked Questions
Can large language models actually reason?
Not in the formal sense. LLMs are next-token predictors trained to produce the most likely next token given prior context. Apple's GSM-Symbolic study (ICLR 2025) found that adding one irrelevant sentence to a math problem caused accuracy to fall by up to 65 percent across top models including GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro, and Llama 3.1 405B. A formal reasoning system would be unaffected by irrelevant information. The output looks like reasoning because the patterns of reasoning appear in the training data, not because reasoning is occurring.
What is next-token prediction?
Next-token prediction is the mechanism every modern LLM uses. The model takes your input as a sequence of tokens (roughly words or parts of words), computes a probability distribution over its 32,000+ token vocabulary for the next token, picks one, and adds it to the context. Then it repeats. There is no separate reasoning engine underneath. Even reasoning models like OpenAI o1, o3, and DeepSeek-R1 use the same underlying mechanism. They differ in training data and inference scaffolding, not architecture.
Why does it matter that LLMs use pattern matching instead of reasoning?
It changes how you should evaluate capability claims and where you can safely deploy AI. Pattern matching works well when your business context resembles the training data. It works inconsistently on multi-step problems where errors compound. It cannot reliably handle formal deduction, planning in unfamiliar environments, or verification of its own outputs. Knowing this lets you set appropriate guardrails, decide how much autonomy to give an AI system, and avoid being surprised when the model fails on problems whose surface looks unfamiliar.
Continue Reading
Your AI Can't Reason. But You Can Still Get Reliable Results.
AI doesn't need to reason to be reliable. It needs problems with verifiable answers. A four-question framework for where AI works in the enterprise.
Your AI Model Isn't Reasoning. It's Searching.
Oxford's HorizonMath benchmark shows AI models improving two unsolved math problems. The improvements came from search, not reasoning.
If Mythos Can Break Code, Can It Break Patents?
If AI can find software vulnerabilities at scale, can it design around patent claims? The same pattern-matching capability, applied to a new domain.
Evaluating AI capability claims for your business?
I help mid-market companies separate what AI can actually do from what vendors say it can do. Let's talk about your specific deployment.
Let's Talk