Before You Let AI Act Alone, Ask This One Question

President, Zaruko
Table of Contents

A client asked me recently whether AI can be trusted to act without human supervision. It's a reasonable question, and it comes up constantly as more businesses deploy AI tools for real work.
My answer: it depends entirely on what happens when the AI is wrong.
That's not a dodge. It's the only honest framework for making this decision. The question isn't whether AI is capable. The question is what a mistake costs you.
The Variable That Changes Everything
Most AI oversight decisions hinge primarily on one question: how reversible is the error?
Can the output be corrected before it causes harm? A draft email sitting in a folder costs nothing to fix. That same email sent to a client cannot be recalled. Same AI, same task, completely different risk profile. The tool didn't change. The cost of failure did.
This is how you should evaluate every AI deployment. Not "is this AI good enough?" but "if it gets this wrong, what breaks, and can we fix it?"
Consider a few concrete examples. AI classifying inbound support tickets and routing them to the right team: if it misfires, a human sees the wrong ticket, routes it manually, and the error costs thirty seconds. AI drafting a client proposal that a human reviews before sending: the human catches the hallucination, corrects it, no one is the wiser. AI sending that proposal directly: now the client has received fabricated figures, and you're in damage control.
The work is identical in all three cases. The exposure is not.
Three Questions Before You Remove the Human
Before you let AI act without review, answer these three questions directly.
First: if it's wrong, what breaks? Some errors are embarrassing. Some are expensive. Some are legally actionable. Classify the severity before you decide on the oversight model, not after an incident.
Second: can the mistake be undone? A miscategorized document can be reclassified. A wrong invoice payment is harder to recover. A published article with fabricated statistics is nearly impossible to fully retract, even with a correction. Irreversible mistakes demand human checkpoints by default.
Third: is there an audit trail? If AI acts and something goes wrong, can you reconstruct what happened and why? If the answer is no, you do not have a governance model, you have a liability.
Low severity, reversible, auditable: AI can probably run without a human in the loop. High severity, irreversible, no audit trail: the human stays involved. Most real business tasks land somewhere in the middle, which means your oversight model should be calibrated, not binary.
Where the Data Points
The evidence points in the same direction. Leading models have improved sharply on some grounded tasks, but factual reliability still drops meaningfully on harder, open-ended questions. Stanford's 2025 AI Index reports hallucination rates near 1.3% on a summarization benchmark for the best models, while newer factuality benchmarks remain difficult even for top systems.1 That gap is exactly why oversight has to be calibrated to the task, not the model.
Hallucination rates complicate the picture further. The same AI that handles structured data with near-perfect accuracy can confidently fabricate information when asked something it doesn't actually know.
This is not an argument against AI. It is an argument for deploying it with clear eyes about what it does well and where it still fails.

AI Oversight Decision Matrix: how task reversibility and error severity should determine the human oversight model.
What I Mean by "Human in the Loop"
There is a meaningful difference between a human rubber-stamping AI output and a human actually reviewing it. Both are technically "in the loop." Only one catches errors.
The oversight that works is specific: a defined review step with a clear scope. The reviewer knows what to check. They have the context to judge whether the output is correct. And they have the authority to stop the process if it isn't.
That review step does not need to be slow. For many tasks, a trained human can audit AI output in two minutes. The review exists not because AI is untrustworthy in principle, but because the cost of an undetected error exceeds the cost of the check.
This is also not a permanent arrangement. As AI tools improve on specific tasks and as you build confidence in their performance in your particular context, you can narrow or remove oversight for those tasks. The key word is specific: confidence earned on one task does not transfer automatically to another.
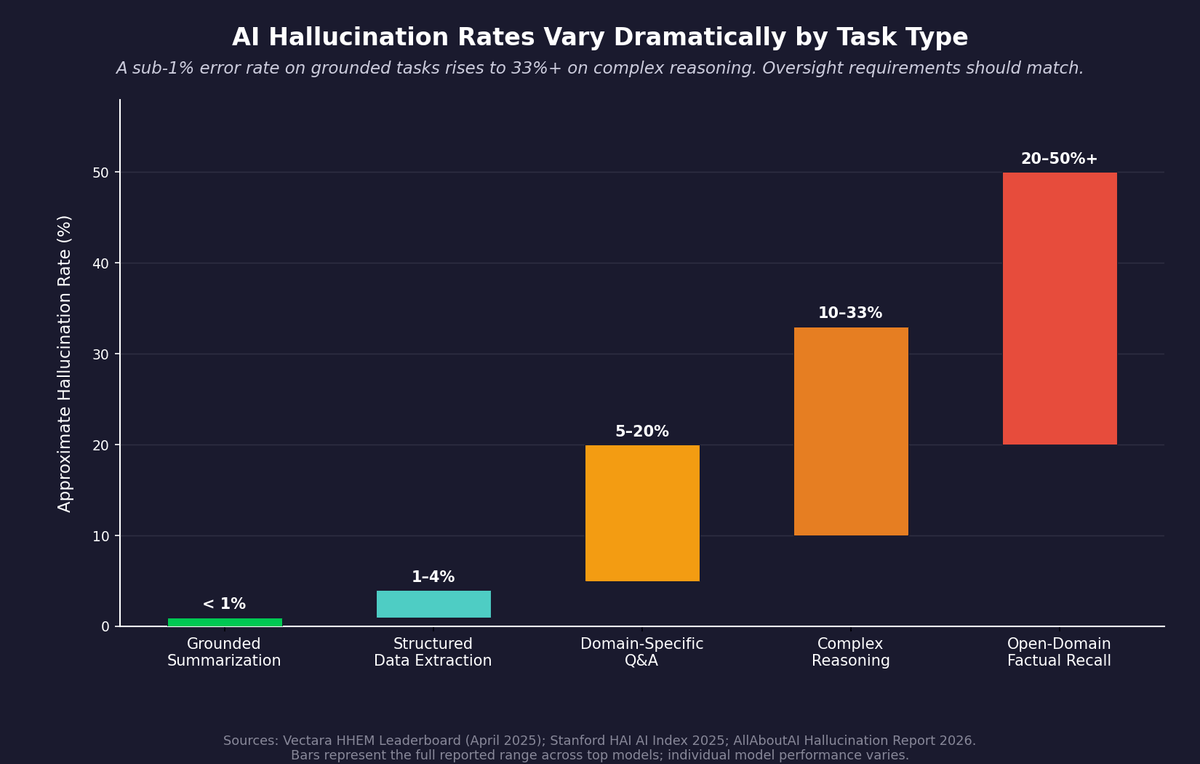
AI Hallucination Rates by Task Type: the gap between grounded tasks and complex reasoning explains why oversight requirements vary by use case.
What 20 Failures Taught Me
I want to give you a concrete example, because the abstract framework only goes so far.
Last week I used Google's NotebookLM to generate an infographic for a Zaruko Insights article. NotebookLM is an impressive product. It analyzes source documents and produces visual summaries, audio overviews, and slide decks grounded in the material you upload. I use it regularly and find it valuable.
I gave it a careful, detailed prompt. I specified what the infographic should include, what to exclude, the style I wanted, and I explicitly instructed it to check spelling before generating.
The first output had errors. So did the second. And the third. Over 20 iterations, I encountered fabricated statistics that weren't in my source material, spelling mistakes despite the explicit instruction to check, and content hallucinated from thin air. NotebookLM was generating outputs that looked polished and professional. They just weren't accurate.
I also tried using Claude to review the generated images for errors. It consistently missed them. AI checking AI is not a quality control model. It is a way to feel productive while errors survive.
Iteration 21 was clean. That's the one that ran on zaruko.com.
A detailed prompt is necessary. It is not sufficient. The human review is what turned 20 flawed outputs into one publishable one. If I had automated the publish step, the first version would have gone live.
The Right Mental Model
Think of AI the way you think about a talented junior hire on their first week. They work fast. They produce volume. They sometimes miss context you consider obvious. You don't let them send client-facing work without review, not because they're bad at their job, but because they haven't yet earned autonomous authority in your specific context, with your specific clients, at your specific standards.
That's not a knock on the hire. It's a management decision based on risk tolerance.
The same logic applies to AI. The question is never "is this AI good enough in the abstract?" The question is: in this context, with these stakes, what is the cost of an error I didn't catch?
Today there are still relatively few high-stakes business actions AI should take entirely unsupervised. There are a large number it can handle extremely well with a human in the loop. That's not a limitation. It's a practical deployment model that reflects where the technology actually is, as opposed to where the marketing says it is.
Stay in the room. For now, it's worth it.
Sources
- Stanford Human-Centered AI Institute, "AI Index 2025 Annual Report" (hallucination rates near 1.3% on summarization benchmarks for top models; factuality benchmarks remain challenging). ↑
Frequently Asked Questions
When can AI act without human supervision?
AI can act without human supervision when errors are low-severity, reversible, and auditable. For example, classifying inbound support tickets or sorting documents: if the AI misfires, a human catches it quickly and the cost is minimal. When errors are high-severity, irreversible, or lack an audit trail (like sending client proposals or publishing content), human review should stay in the loop. The decision hinges on one question: what happens when the AI is wrong?
How reliable is AI and how often does it hallucinate?
AI reliability varies sharply by task type. Stanford's 2025 AI Index reports hallucination rates near 1.3% on summarization benchmarks for the best models, but factuality benchmarks on harder, open-ended questions remain challenging even for top systems. The same AI that handles structured data with near-perfect accuracy can confidently fabricate information on questions it doesn't actually know. This is why oversight should be calibrated to the task, not the model.
What is the right framework for AI oversight decisions?
Ask three questions before removing the human: (1) If it's wrong, what breaks: embarrassing, expensive, or legally actionable? (2) Can the mistake be undone: a miscategorized document vs. a published article with fabricated statistics? (3) Is there an audit trail: can you reconstruct what happened and why? Low severity + reversible + auditable = AI can run autonomously. High severity + irreversible + no audit trail = human stays involved. Most tasks land in the middle, requiring calibrated oversight.
Continue Reading
Your AI Pilot Worked. That's the Worst Thing That Could Have Happened.
88% of AI proofs-of-concept never reach production. The problem isn't the technology.
AI Can Write. It Cannot Think.
Writing quality and factual accuracy are independent. LLMs optimize for the first.
Your Engineering Team Has Most of the Right Practices. It's the Last Four That Make the Difference.
Most teams have the rituals but lack the results. The difference is four decision-quality practices.
Deciding where AI needs oversight in your business?
I help mid-market companies build practical oversight models that match the risk: not too much, not too little. Let's talk about your specific deployment.
Let's Talk