
Table of Contents

I recently wrote about an AI-generated market analysis that scored 9 out of 10 on its own opportunity metric but collapsed under 15 minutes of basic fact-checking. Several people asked the same question: if the analysis was so wrong, why was it so convincing?
The answer is not a bug. It is the fundamental architecture of how these systems work. And understanding it changes how you should use every AI-generated document that crosses your desk.
Language Models Model Language, Not Knowledge
The name tells you everything if you take it literally. A large language model is a model of language. It is a statistical system trained on enormous volumes of text that has learned, with remarkable precision, what good writing looks like. It knows the patterns of a McKinsey report. It knows the structure of a competitive analysis. It knows that when you write a market sizing section, numbers should be cited with sources and growth rates should compound over five-to-ten year horizons. It knows that executive summaries are direct and that recommendations come in groups of three to five.
What it does not have is a representation of whether any specific claim is true.
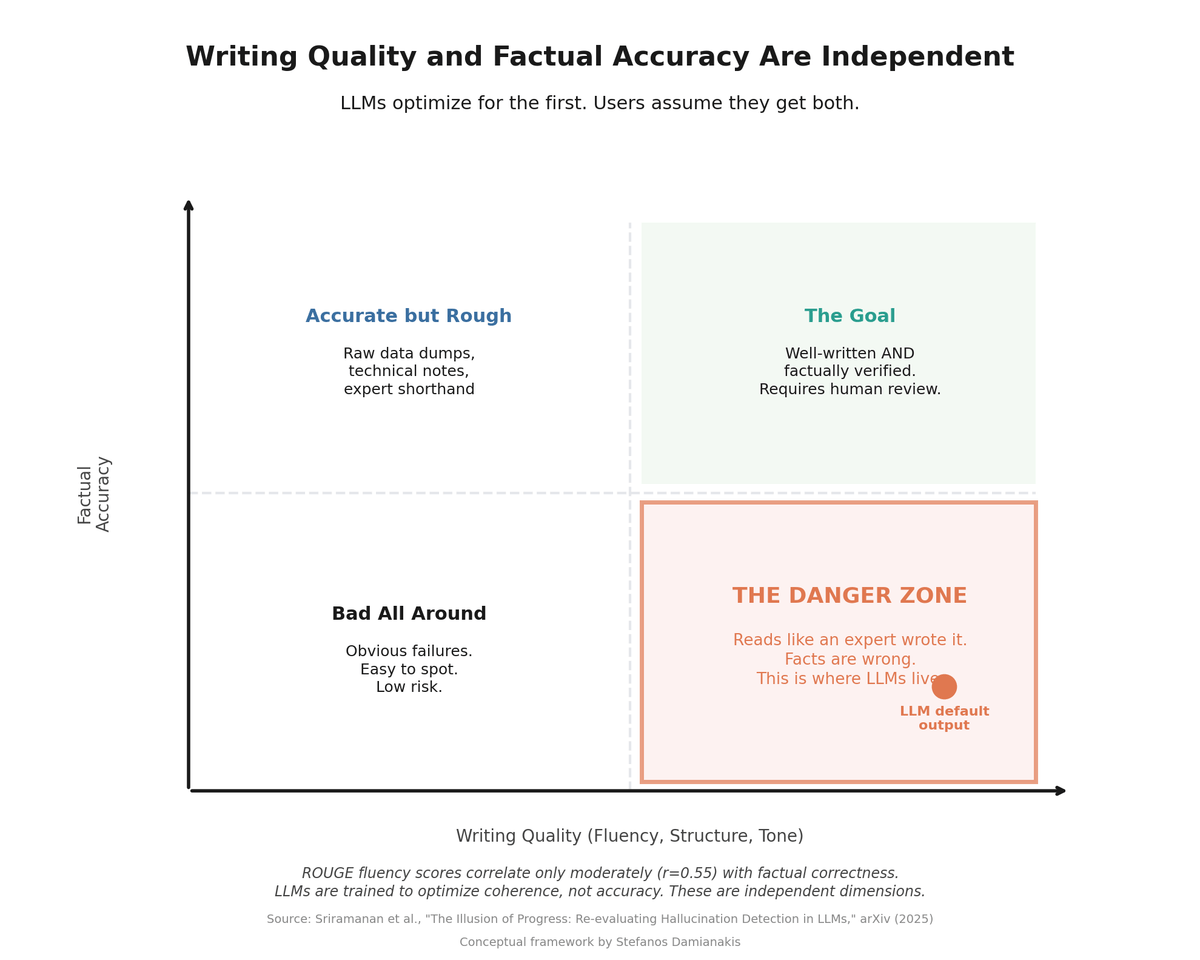
Writing quality and factual accuracy are independent dimensions. LLM default output lands in the Danger Zone.
This is not a limitation that will be fixed in the next model version. It is a structural feature of the architecture.1 LLMs work by predicting the next token in a sequence. Given the tokens that came before, what token is most likely to come next? That prediction is based on patterns learned from training data. The system has seen millions of competitive analyses. It knows what they look like. It can produce new ones that are structurally indistinguishable from the real thing. But it is not researching. It is not reasoning about market dynamics. It is completing a pattern.
Training Data is Not a Knowledge Base
People sometimes assume that because LLMs were trained on vast amounts of internet text, they have access to that information the way a database has access to its records. This is wrong in an important way.
During training, the model processes text and adjusts billions of numerical parameters to get better at predicting the next word. The training data is not stored. It is dissolved into the model's weights. What remains is statistical associations between patterns of language, not a retrievable record of facts. When you ask an LLM about the competitive landscape for AI agent verification, it is not looking up that information. It is generating text that matches the pattern of what a response to that question would look like, drawing on the statistical residue of everything it processed during training.
Sometimes those patterns produce accurate information, because accurate information appeared frequently and consistently in the training data. But sometimes they produce plausible-sounding nonsense, because the model has no mechanism for distinguishing between the two. It treats "Google Cloud launched an AI Agent Marketplace in 2025" and "No competitors exist in this space" as equally valid completions of a sentence, depending on which pattern scores higher in the local context. On standardized factual questions, even the best frontier models answer fewer than half correctly without external tools.2 And they consistently overestimate their own accuracy by 20% to 60%.34
How This Creates Convincing Failures

The quality of the writing tells you nothing about the quality of the facts.
This architecture explains exactly why the market analysis I reviewed was simultaneously well-written and wrong. The writing quality and the factual accuracy come from completely different mechanisms.5
The writing quality comes from pattern matching on language structure. The model has seen thousands of high-quality market analyses. It knows the vocabulary, the sentence structure, the way data is presented, the way recommendations are framed. This is what LLMs are excellent at, and it is why the output reads like it was written by a competent analyst.
The factual claims come from a completely different process: statistical associations in the training data, filtered through the local context of the prompt. The model does not verify claims against reality. It does not search the internet for current competitors. It generates text that fits the pattern. If the pattern it learned says that niche markets often have no dominant players, it will confidently write that no competitors exist, because that is what competitive analyses of niche markets often say.
The result is a document where the quality of the writing actively works against the reader's ability to spot errors. We are trained from childhood to equate fluency with intelligence. When someone writes well, we assume they have thought carefully. With LLMs, that assumption breaks down completely. The quality of the prose tells you nothing about the quality of the reasoning, because there is no mechanism for verifying claims against reality.6 There is only pattern completion.
What This Means For Decision-Makers
Once you understand this architecture, the rules for using AI-generated analysis become clear.
Trust the structure, verify the substance. LLMs are good at organizing information into useful frameworks. They can give you a template for a competitive analysis, a structure for a business case, or a framework for evaluating a market. Use that. But treat every specific claim as unverified until you have checked it yourself.
Be more skeptical when the writing is better. This is counterintuitive but important. A polished, well-structured AI output is more dangerous than a rough one, because it is harder to maintain critical distance from something that reads like it was written by an expert. The quality of the prose is independent of the quality of the facts.
Understand what "trained on the internet" actually means. It does not mean the model has access to current information. It means the model has statistical patterns derived from text that existed at the time of training. Those patterns degrade rapidly for any domain where the facts change quickly, which includes most business and technology markets.
Use LLMs for drafting, not for concluding. The best use of these tools in a business context is generating first drafts, identifying questions to investigate, and structuring thinking. The worst use is treating the output as finished analysis. The model can write the report. You still have to do the research.
The Bigger Pattern
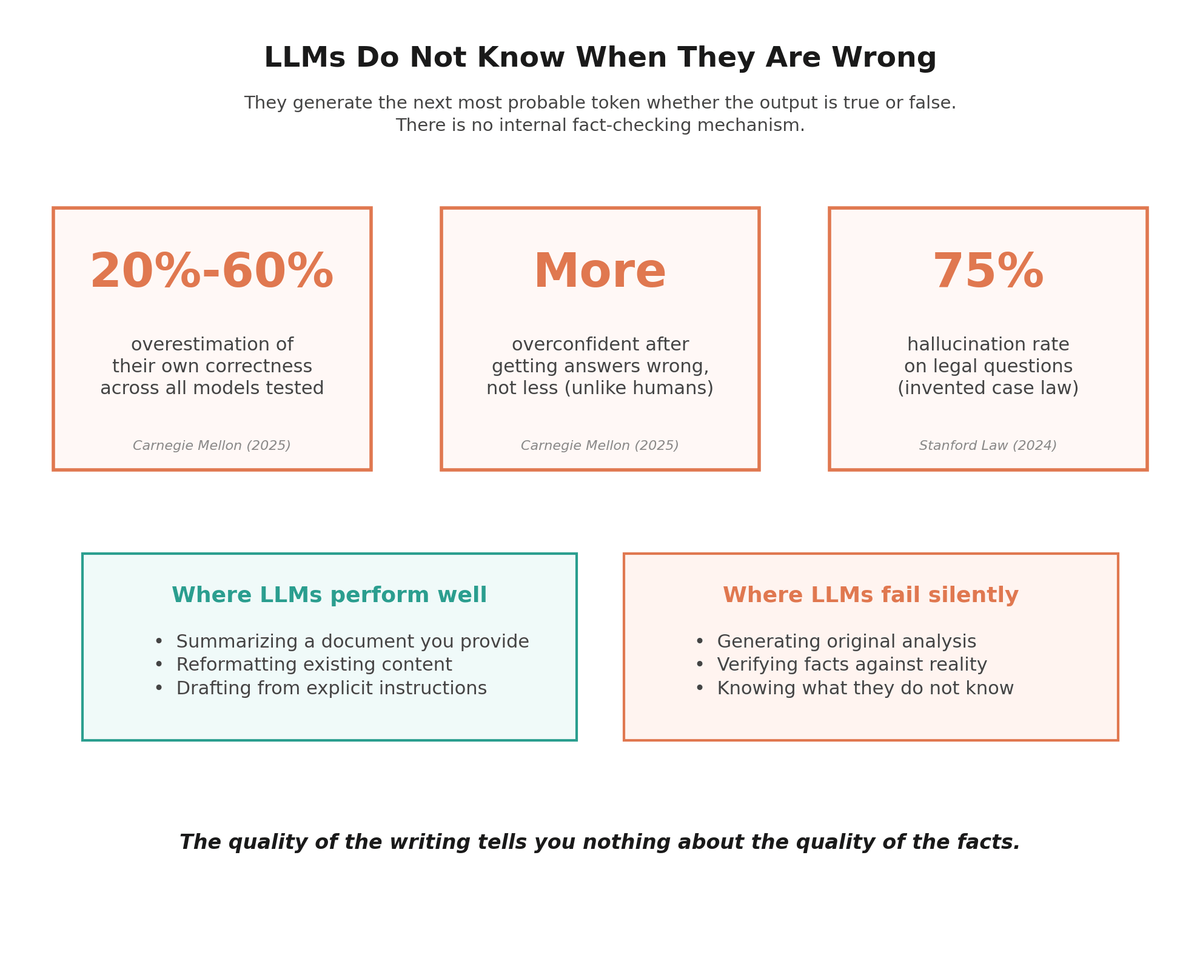
LLMs generate the next most probable token whether the output is true or false. There is no internal fact-checking mechanism.
Every major failure mode in enterprise AI right now traces back to this same root cause: confusing fluent language with reliable knowledge. The market analysis that confidently reports no competitors. The customer service bot that invents a return policy. The legal brief that cites cases that do not exist.7 The financial model that uses plausible but fabricated data points. Every one of these is an LLM doing exactly what it was built to do: produce text that matches the pattern of a correct answer, without any mechanism for knowing whether the answer is actually correct.
The companies that will use AI effectively are the ones that internalize this distinction. Language models are extraordinary tools for working with language. They are not knowledge systems. They are not research tools. They are not analysts.8 They optimize coherence, not correspondence to reality. The problems start when we ask them to be something they are not.
The governance risk is real and growing. Boards approve strategies built on AI-generated analysis that no one verified. Internal audits miss errors because the output reads like it was written by a senior analyst. Compliance teams sign off on documents where the regulatory citations are fabricated. Every one of these failures traces back to the same root: treating fluent language as reliable knowledge.
AI can write the first draft faster than any human. But the first draft is where the work begins, not where it ends.
Sources
- "Survey and Analysis of Hallucinations in Large Language Models: Attribution to Prompting Strategies or Model Behavior," Frontiers in Artificial Intelligence, August 2025. Formalizes the mathematical tradeoff: "optimization of fluency and coherence often conflicts with factual grounding." frontiersin.org ↑
- "Measuring Short-Form Factuality in Large Language Models" (SimpleQA) by Wei et al., OpenAI, November 2024. On adversarial factual questions, GPT-4o scored 38.2% correct, o1-preview scored 42.7%, and Claude 3.5 Sonnet scored 28.9%. arxiv.org ↑
- "Quantifying Uncert-AI-nty: Testing the Accuracy of LLMs' Confidence Judgments" by Trent Cash et al., Carnegie Mellon University, published in Memory & Cognition, July 2025. LLMs overestimate the probability that their answers are correct by 20% to 60%, and unlike humans, they become more overconfident after performing poorly. doi.org ↑
- "Large Language Models are Overconfident and Amplify Human Bias" by Fengfei Sun et al., May 2025. All five LLMs studied overestimated the probability that their answers were correct by 20% to 60%, and LLM bias increased sharply relative to humans when confidence decreased. arxiv.org ↑
- "The Illusion of Progress: Re-evaluating Hallucination Detection in LLMs" by Sriramanan et al., arXiv, August 2025. ROUGE fluency scores show only a moderate correlation (r=0.55) with actual factual correctness, demonstrating that standard quality metrics do not reliably measure accuracy. arxiv.org ↑
- "Hallucination to Truth: A Review of Fact-Checking and Factuality Evaluation in Large Language Models," arXiv, August 2025. LLMs' core training objective optimizes for coherence and contextual appropriateness rather than factual accuracy. Standard metrics "do not measure the factual correctness. High overlap or semantic scores may still correspond to factually incorrect content." arxiv.org ↑
- "Hallucination is Inevitable: An Innate Limitation of Large Language Models." Stanford legal hallucination study found LLMs hallucinated at least 75% of the time when asked about court rulings, inventing non-existent cases with realistic names and fabricated legal reasoning. arxiv.org ↑
- "A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions," ACM Transactions on Information Systems, 2025. Comprehensive survey documenting how LLMs prioritize "fluency at the expense of faithfully adhering to the source context." doi.org ↑
Frequently Asked Questions
Why does AI-generated content sound convincing but contain factual errors?
LLMs optimize for writing quality (fluency, structure, and tone), not factual accuracy. These are independent dimensions. Research shows fluency scores correlate only moderately (r=0.55) with factual correctness. The model predicts the most likely next word based on patterns in training data, not by verifying claims against reality. A polished, professional-sounding document can be completely wrong.
Can AI replace human analysts for business research and due diligence?
No. AI can generate first drafts, organize frameworks, and surface themes, but it cannot verify facts, reason about market dynamics, or distinguish reliable from unreliable claims. On adversarial factual questions, even the best frontier models answer fewer than half correctly. Companies that treat AI output as finished analysis risk making decisions based on fabricated data.
What is the difference between coherence and factual accuracy in AI output?
Coherence means text flows logically and reads professionally. Factual accuracy means the claims correspond to reality. LLMs are trained to maximize coherence, not accuracy. The optimization of fluency and coherence often conflicts with factual grounding. This is why AI can produce a market analysis that reads like expert work but contains fabricated competitors, invented statistics, and fictional case law.
Continue Reading
First Principles of AI
Ten foundational principles for evaluating AI claims and making better decisions.
The Problem with Feeding Everything to Your AI
The most expensive mistake in enterprise AI is assuming more data produces better answers. Research going back 75 years explains why it doesn't.
The AI Analysis That Analyzed Itself Into Nonsense
A 9-out-of-10 AI-generated market analysis fell apart in 15 minutes of fact-checking.
Using AI-generated content for business decisions?
I help companies build the judgment layer between AI output and real decisions. Let's talk about using AI effectively without the blind spots.
Let's Talk