The AI Analysis That Analyzed Itself Into Nonsense

President, Zaruko
Table of Contents

I recently looked at a market analysis for a startup idea in the AI agent space. It had competitive landscapes, TAM calculations, a Hormozi value equation breakdown, keyword research, community sentiment analysis, and an opportunity score of 9 out of 10. It was well-written and convincing. It was also clearly AI-generated.
It took me about 15 minutes to find problems that made the entire analysis unreliable.
This is not a story about one bad report. It is a pattern I see constantly, and it has real consequences for companies making real capital allocation decisions based on AI-generated research.
The Numbers Tell the Story
Before I walk through the specific problems with this report, consider the broader context. The gap between what companies expect from AI and what they actually get is growing, not shrinking.
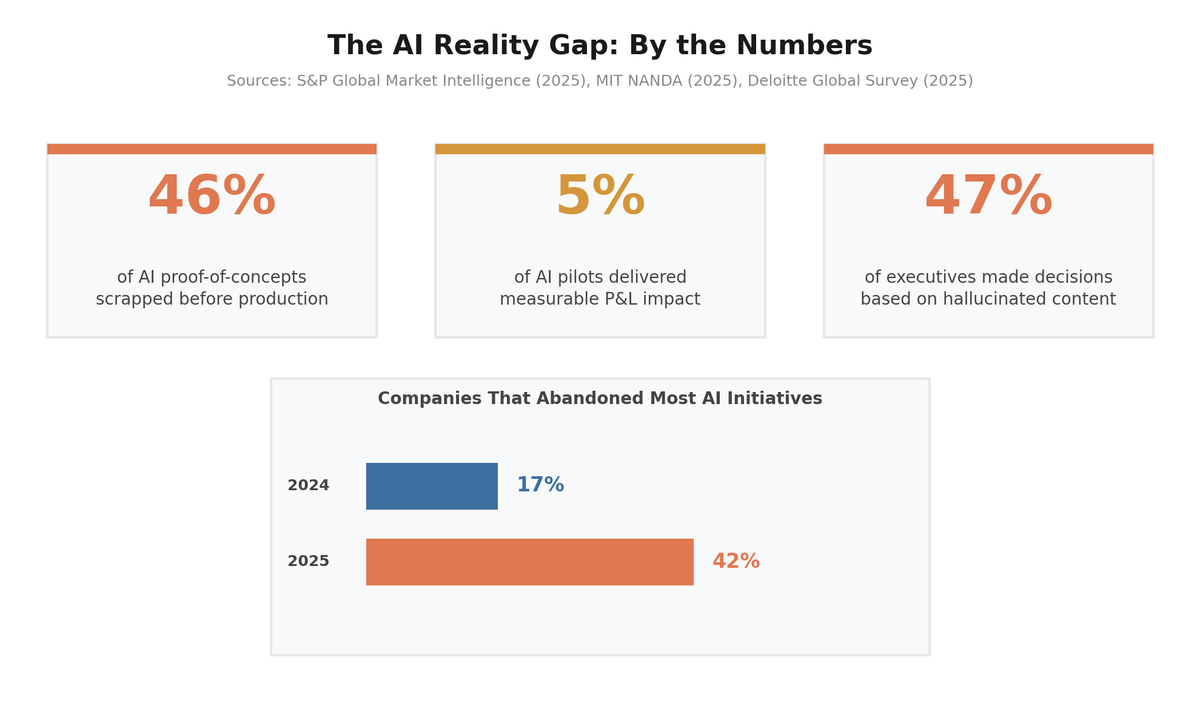
The AI Reality Gap: By the Numbers
According to S&P Global Market Intelligence's 2025 survey of over 1,000 enterprises, the share of companies abandoning most of their AI initiatives jumped from 17% to 42% in a single year. The average organization scrapped 46% of AI proof-of-concepts before they reached production.1 MIT's NANDA study found that only 5% of enterprise AI pilots delivered measurable P&L impact.2 And a 2025 Deloitte Global Survey found that 47% of enterprise AI users admitted to making at least one major business decision based on hallucinated content.3
That last number deserves your full attention. Nearly half of enterprise AI users have made a significant business decision based on information the AI made up. Now imagine combining that tendency with an AI tool specifically designed to produce the kind of analysis that drives investment decisions. That is exactly what happened with the report I reviewed.
What the Report Got Right
The underlying pain point was legitimate. Enterprise procurement teams buying AI agents have a trust and verification problem. When a customer service agent hallucinated pricing to 400 customers before anyone caught it, the company involved did not have a good way to evaluate the agent beforehand. There is no Consumer Reports for AI agents. Procurement teams are making six-figure commitments based on demos and pitch decks.
The report correctly identified that the AI agent market is growing fast and that trust infrastructure is lagging behind deployment speed. Directionally, the thesis had merit.
Then the specifics fell apart.
Where It Collapsed
The report claimed there were "no direct competitors" for centralized AI agent verification. A single web search proved this wrong. Google Cloud has an AI Agent Marketplace with built-in validation frameworks. Oracle has an AI Agent Marketplace with a 21-point enterprise readiness checklist. Credo AI appears in Gartner's Market Guide for AI Governance Platforms. Tumeryk has an AI Trust Score product. Sumsub launched an AI Agent Verification product just weeks ago. The evaluation tooling space, including companies like Patronus AI, DeepEval, and Langfuse, is crowded and growing.
The report did not find any of these because the AI generating it did not actually search for them. It synthesized a competitive landscape from its training data and concluded the field was empty. This is the equivalent of a junior analyst writing a market report without picking up the phone or opening a browser.
The market sizing was equally misleading. The report cited the total AI agent market at $7.6 billion growing to $182 billion by 2033. But the product in question was a verification and scoring platform, not an AI agent. The serviceable addressable market for agent verification is a small fraction of the total agent market, and most of that addressable market is being absorbed by the platform providers themselves who bundle verification into their own ecosystems at no additional cost.
The revenue model proposed charging developers $149 to $499 for a verification badge, and enterprises $500 to $2,000 per month for API access. This is a two-sided marketplace cold start problem disguised as a pricing table. Why would enterprises trust a new platform's verification over Google's or Oracle's built-in vetting? Why would developers pay for a badge that no buyer has asked for yet?
The execution timeline suggested building a credible MVP in one to two weeks. Building evaluation criteria that enterprise procurement teams actually trust requires months of calibration with real buyers, testing infrastructure, and domain expertise. An Airtable directory with self-generated scores does not meet the bar that the report's own target customer demands.
Why This Matters Beyond One Bad Report
The report looked professional. It used established frameworks. It had charts, scores, matrices, and keyword data. If you did not already know the market, you would have no reason to question it. That is exactly the problem.
AI-generated analysis creates false confidence through the appearance of rigor. The format borrows from legitimate research methodology, but the substance skips the hard work that makes real analysis valuable: primary research, competitive validation, buyer interviews, and critical reasoning about structural market dynamics.
This is not a hypothetical risk. Companies are using tools like this to make investment decisions, resource allocation decisions, and build-versus-buy decisions. A CEO at a mid-market company could look at a report like this, see the 9-out-of-10 opportunity score and the $182 billion market projection, and commit capital based on it. Larger companies have staff who should catch these problems, but the quality of the output is good enough to slip past anyone who is not already an expert in the specific market being analyzed.
The irony is not lost on me. The report was about building trust infrastructure for AI agents. The report itself was generated by an AI agent that could not be trusted to produce reliable analysis.
What To Do About It
AI-generated research is not useless. It can surface themes, organize publicly available data, and accelerate the early stages of market exploration. But it cannot replace the judgment layer. Here is what I tell every operator I work with.
Treat AI-generated competitive analysis as a hypothesis, not a finding. If the report says there are no competitors, that is the starting point for your own search, not the conclusion. The absence of evidence is never evidence of absence, especially when the research agent did not actually look.
Challenge market sizing that conflates TAM with SAM. When a report uses the total market for AI agents to justify a verification platform, it is telling you the tool cannot distinguish between related markets and addressable markets. This is the most common inflation technique in AI-generated business cases, and it makes everything downstream unreliable.
Ask who is already solving this problem as part of something bigger. The most dangerous competitors are rarely standalone companies doing exactly what you plan to do. They are large platforms that bundle your proposed product as a feature of their existing offering. Google, Oracle, Microsoft, and Salesforce are all building agent verification directly into their marketplaces. That is a structural competitive fact that changes the entire business case.
Be skeptical of precision in scoring. A 9-out-of-10 opportunity score implies a level of quantitative rigor that does not exist in the underlying analysis. The score is an output of an AI model processing other AI-generated content. It measures consistency with the model's training patterns, not actual market opportunity.
The Bigger Picture
We are entering a period where AI can produce analysis that is indistinguishable in format from expert work but fundamentally different in reliability. The tools are getting better at presentation. They are not getting better at the kind of critical thinking that makes analysis valuable.
The S&P Global data shows the consequences at scale. In 2024, 17% of companies abandoned their AI initiatives. In 2025, that number hit 42%. The companies that will make good decisions in this environment are the ones that treat AI-generated research as a starting point and invest in the human judgment to validate it. The companies that will make expensive mistakes are the ones that mistake comprehensive formatting for comprehensive thinking.
There is a reason that experienced investors still fly to meet founders, walk factory floors, and call customers before writing checks. The hard work of validation cannot be automated away. AI can make you faster at getting to the right questions. It cannot answer them for you.
Sources
- S&P Global Market Intelligence, "2025 Enterprise AI Survey," survey of over 1,000 enterprises. ciodive.com ↑
- MIT NANDA, "State of AI in Business 2025." Found that 95% of enterprise AI pilots failed to deliver measurable P&L impact. fortune.com ↑
- Deloitte, "Enterprise AI Decision-Making Risks: Global Executive Survey Results," 2025. deloitte.com ↑
Frequently Asked Questions
Why do AI-generated analyses often fail?
AI-generated analyses fail because AI models are pattern matching engines, not reasoning engines. They produce outputs that look professionally formatted and sound authoritative, but they cannot verify whether the facts, numbers, or conclusions are accurate. A common pattern: the AI generates a plausible-looking market analysis with specific percentages and citations, but the numbers are fabricated and the sources don't say what the AI claims.
What percentage of companies are abandoning AI projects?
According to research, 42% of companies that started AI initiatives have since abandoned them. The primary reasons are lack of measurable ROI, difficulty integrating AI into existing workflows, and over-reliance on AI outputs without adequate human oversight. The companies that succeed treat AI as a tool that augments human judgment rather than replaces it.
Continue Reading
First Principles of AI
Ten foundational principles for evaluating AI claims and making better decisions.
AI Can Write. It Cannot Think.
Writing quality and factual accuracy are independent. Understanding why changes how you use every AI output.
Demystifying Agentic AI
What agentic AI actually is, what it isn't, and why most projects fail.
Making decisions with AI-generated research?
I help companies build the judgment layer that turns AI output into reliable analysis. Let's talk about getting the most from AI without the blind spots.
Let's Talk