The Problem with Feeding Everything to Your AI

President, Zaruko
Table of Contents
The most expensive mistake in enterprise AI deployments is not choosing the wrong model. It is assuming that more data produces better answers.
This assumption is wrong. And the research explaining why it is wrong is 75 years old.
Claude Shannon Saw This Coming in 1948
In 1948, mathematician Claude Shannon published "A Mathematical Theory of Communication" in the Bell System Technical Journal.1 The paper founded the field of information theory and remains one of the most cited scientific papers ever written. Scientific American called it the "Magna Carta of the Information Age." The ideas in that paper are not abstract. They are the engineering foundation behind CDs, DVDs, cell phones, modems, computer networks, hard drives, memory chips, encryption, MP3 audio, and high-definition television.8 Every digital system that transmits, stores, or retrieves information operates on Shannon's mathematics. Anthropic named its AI model Claude in his honor, a fitting tribute given how directly his ideas constrain what every AI system, including their own, can and cannot do.
Shannon's central insight was precise: as noise increases in a channel, extracting the true signal becomes harder. He was writing about telegraph systems, but the signal-versus-noise lens applies well beyond communication channels. Data abundance does not produce clarity. Without filtering and structure, it produces noise. This is the same dynamic behind why AI can write convincingly while getting facts wrong. Shannon established this principle 30 years before the personal computer and 50 years before Google. We have been building systems that run into it ever since.
The Web Search Problem
To see how this plays out in practice, go back to the early days of the web.
By the late 1990s, the internet already contained millions of pages. Search engines existed, but they returned poor results. The problem was not a lack of data. It was too much of it with no way to rank it. Search for "electricity" and you found hundreds of millions of pages, each treated as equally valid. Without a way to rank relevance, results were essentially a lottery.
Google's major advance was not crawling more pages. It was PageRank, a key relevance signal based on the quality and quantity of links pointing to a page.2 The logic was that a page linked to by many authoritative sources was more likely to contain what you were looking for than a page with no such endorsements. Better ranking, not more data, is what made web search useful.
The lesson is direct: volume without prioritization produces noise, not answers.
The Precision-Recall Tradeoff Is Not New Either
Information retrieval researchers codified this tension decades before modern AI existed.
Manning, Raghavan, and Schutze's standard textbook on information retrieval states it plainly:3 improving recall, meaning finding more possible results, typically reduces precision, meaning how accurate those results are. Broaden the search to include more documents and you introduce more irrelevant material alongside the relevant. Narrow it and you risk missing something important.
Every retrieval system operates on this tradeoff frontier: there is no free lunch that maximizes both precision and recall simultaneously. Every AI system that retrieves information to answer a question faces the same constraint. This has been known and documented in computer science for more than 50 years.
Where RAG Fits In, and Where It Falls Short
Retrieval-Augmented Generation, or RAG, is the most widely used approach for connecting AI models to a company's internal documents, knowledge bases, and data. The idea is sound: instead of feeding an entire document corpus to the model, the system retrieves a semantically relevant subset first, then passes only that subset to the model as context.
RAG moves in the right direction. It is a genuine improvement over the naive approach of dumping everything in. But the research shows the underlying problem persists in ways most organizations do not anticipate.
The first issue is over-retrieval. A 2025 paper presented at ICLR, "Long-Context LLMs Meet RAG," tested what happens as you increase the number of retrieved passages fed to the model.4 Performance initially improves as more relevant context is added. Then it declines. The relationship is an inverted U. The reason: as you retrieve more passages to improve recall, you inevitably pull in irrelevant ones alongside the relevant ones. The researchers call these "hard negatives." Hard negatives do not just add noise. They actively mislead the model, producing wrong answers even when the correct information is present elsewhere in the retrieved context. This is the mechanism behind AI analyses that score well on their own metrics but collapse under basic fact-checking.
The second issue is chunk size. RAG systems divide documents into chunks before indexing them. The size of those chunks is typically set once at deployment and never revisited. AI21 published research showing substantial retrieval gains from query-dependent chunking, with benchmark improvements reaching the 30%+ range in some settings.5 The right chunk size depends on the specific question being asked. A chunk size that works well for one question fails for another. Most enterprise deployments do not account for this. They pick a default, usually somewhere between 500 and 800 tokens, and treat it as solved.
The precision-recall tradeoff does not disappear in a RAG system. It moves downstream.
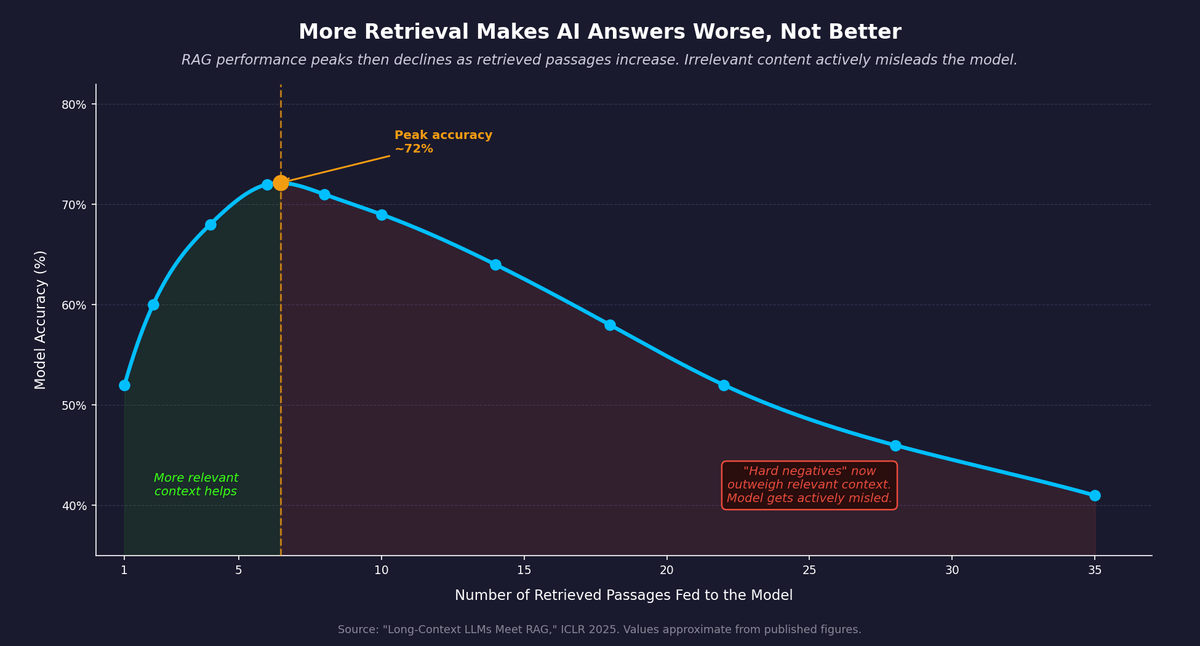
Figure 1: RAG performance peaks then declines as retrieved passages increase. Irrelevant content actively misleads the model. Source: "Long-Context LLMs Meet RAG," ICLR 2025.
The Lost-in-the-Middle Problem
Even after retrieval narrows the data down, the model faces another constraint that most practitioners underestimate.
Researchers at Stanford and MIT published a study in the Transactions of the Association for Computational Linguistics in 2024 examining how language models use information in long contexts.6 They found a U-shaped performance curve. LLMs perform best when relevant information appears at the beginning or end of the context window. Performance degrades significantly when relevant information is in the middle. The model is not processing all retrieved content equally. It systematically underweights information buried in the center of what it receives. The Liu et al. study found that in some configurations, accuracy at the middle position fell below the closed-book baseline, meaning the model performed worse with the correct document present than with no documents at all.
A 2025 study published at EMNLP pushed this further.7 Researchers tested five models across math, question answering, and coding tasks. Even when models could perfectly retrieve all relevant information, reasoning performance still degraded substantially: between 14 and 85 percent across models and task types, simply because the input was longer. The sheer length of the context hurt performance independent of retrieval quality.
This appears to be a recurring structural limitation of current LLM architectures, not something buyers should assume will vanish in the next model release. Better models raise the threshold at which performance degrades. They do not eliminate the effect. Building around it requires deliberate design decisions, not a larger context window.
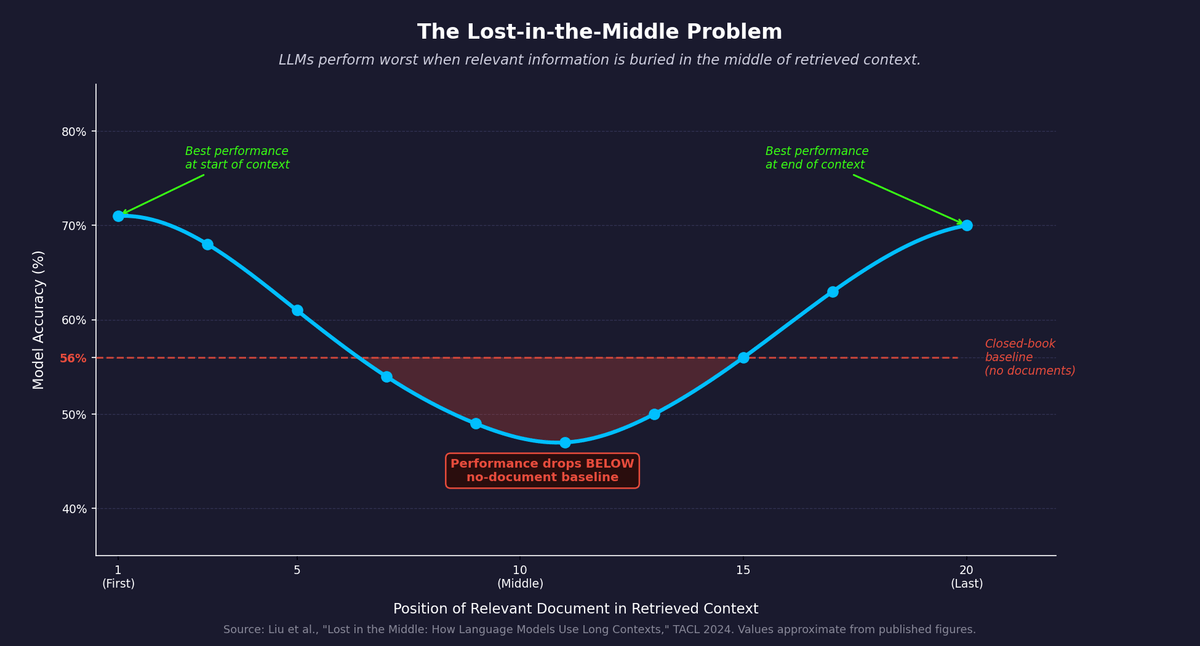
Figure 2: U-shaped LLM accuracy by position of relevant document in retrieved context. Performance at the middle drops below the closed-book baseline (no documents). Source: Liu et al., "Lost in the Middle," TACL 2024.
The Context Window Arms Race Makes This Worse, Not Better
A reasonable response to everything described above is: just use a bigger context window. If the model can hold more, retrieve more, and reason over more simultaneously, the data filtering problem becomes less critical. This is the implicit promise behind the industry's current direction.
The context window race is real. Google introduced Gemini 1.5 Pro in early 2024 and soon emphasized 1M-token long-context capability. GPT-4.1 followed with 1 million tokens. Meta's Llama 4 reached 10 million.9 Every major frontier model has moved aggressively in this direction, and vendors market these capabilities as a step toward putting entire document corpora into a single prompt.
The research does not support this conclusion. A July 2025 technical report from Chroma Research evaluated 18 LLMs on long-context tasks, including the leading frontier models GPT-4.1, Claude 4, Gemini 2.5, and Qwen3.9 The most widely used benchmark for long-context capability, called Needle in a Haystack, tests only whether a model can find a specific sentence in a long document. It does not test reasoning, synthesis, or handling of ambiguous or semantically similar content. Models that score near-perfectly on that benchmark show meaningful degradation on tasks that resemble actual business questions.
The Du et al. findings make clear why:7 context length alone degrades reasoning performance substantially, even with perfect retrieval. The context window is not the bottleneck. The signal-to-noise ratio is.
Larger context windows do not solve the problem this post describes. They amplify it. A model given 500 pages of loosely filtered internal documents has more irrelevant material to contend with, not less. The lost-in-the-middle effect gets worse. The hard negatives from over-retrieval multiply. Context window size is a benchmark number. What matters is what goes into that window and how precisely it has been filtered.
The Problem Is Structural, Not Fixable by Scaling
Everything described above shares a common cause. The amount of data going into your AI system is not the variable that determines answer quality. The signal-to-noise ratio of that data is.
The companies that understand this will spend their time getting better answers. The ones that don't will spend their time adding more data and wondering why the answers keep getting worse.
The fix exists. It requires engineering discipline, not a bigger model. That is what the next post covers.
Sources
- Claude E. Shannon, "A Mathematical Theory of Communication," Bell System Technical Journal, Vol. 27, 1948. PDF. ↑
- Larry Page and Sergey Brin, "The Anatomy of a Large-Scale Hypertextual Web Search Engine," Stanford University, 1998. IEEE Engineering and Technology History Wiki. ↑
- Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schutze, Introduction to Information Retrieval, Cambridge University Press, 2008. Online edition. ↑
- "Long-Context LLMs Meet RAG," ICLR 2025. PDF. ↑
- AI21, "Chunk Size Is Query-Dependent: A Simple Multi-Scale Approach to RAG Retrieval," 2026. ai21.com. ↑
- Nelson F. Liu et al., "Lost in the Middle: How Language Models Use Long Contexts," Transactions of the Association for Computational Linguistics, Vol. 12, 2024. ACL Anthology. ↑
- Yufeng Du et al., "Context Length Alone Hurts LLM Performance Despite Perfect Retrieval," Findings of EMNLP 2025. arXiv. ↑
- Erico Guizzo, "The Essential Message: Claude Shannon and the Making of Information Theory," MIT Comparative Media Studies, 2003. MIT. ↑
- Kelly Hong, Anton Troynikov, and Jeff Huber, "Context Rot: How Increasing Input Tokens Impacts LLM Performance," Chroma Research, July 2025. Chroma Research. ↑
Frequently Asked Questions
Why does feeding more data to an AI model make answers worse?
More data increases noise alongside signal. Research shows that as retrieved passages increase, AI performance initially improves then declines because irrelevant content (hard negatives) actively misleads the model. This is the precision-recall tradeoff: broadening retrieval to find more results reduces the accuracy of what's returned. Claude Shannon established in 1948 that as noise increases in a channel, extracting the true signal becomes harder.
What is the lost-in-the-middle problem in large language models?
LLMs perform best when relevant information appears at the beginning or end of the context window. Performance degrades significantly when relevant information is buried in the middle. Stanford and MIT researchers found that in some configurations, accuracy at the middle position fell below the closed-book baseline, meaning the model performed worse with the correct document present than with no documents at all.
Do larger context windows solve the problem of AI answer quality?
No. Research from EMNLP 2025 shows that context length alone degrades reasoning performance by 14 to 85 percent across models, even with perfect retrieval. Larger context windows amplify noise and structural limitations rather than solving them. The bottleneck is not context window size but the signal-to-noise ratio of the data fed to the model.
Continue Reading
Better Data Beats More Data. Here's How to Build for It.
Knowledge graphs, contextual retrieval, and data-centric AI deliver larger gains than model upgrades. Practical architecture for AI systems that prioritize signal over volume.
AI Can Write. It Cannot Think.
Writing quality and factual accuracy are independent. LLMs optimize for the first. Understanding why changes how you use every AI output.
The AI Analysis That Analyzed Itself Into Nonsense
A 9-out-of-10 AI-generated market analysis fell apart in 15 minutes. The pattern behind it explains why 42% of companies are abandoning their AI initiatives.
Getting worse answers from more data?
I help companies build AI systems that prioritize signal over volume. Let's talk.
Let's Talk