Better Data Beats More Data. Here's How to Build for It.

President, Zaruko
Table of Contents

The previous post established the problem. More data makes AI worse. Bigger context windows amplify noise alongside signal. RAG retrieves hard negatives that actively mislead the model. The lost-in-the-middle effect means models often perform worse when relevant information sits in the middle of a long context. The context window arms race is moving in the wrong direction.
None of this is fixed by a better model. It is fixed by better data engineering. Here is what that looks like in practice.
A Better Architecture: Structure Before Retrieval
The problems described in the previous post share a common root. Standard RAG retrieves chunks of text based on semantic similarity. A question arrives, the system finds passages that look related, and passes only that subset to the model as context. The problem is that semantic similarity is a weak proxy for relevance when the answer requires connecting information across multiple documents, understanding how entities relate to each other, or synthesizing patterns that exist across an entire dataset.
This is where knowledge graphs change the architecture.
A knowledge graph is a structured representation of entities and the relationships between them. Instead of storing documents as text chunks, a knowledge graph stores the facts inside those documents as nodes and edges: this product is connected to this supplier, this supplier is subject to this regulation, this regulation was amended on this date. The structure is explicit. Relationships are traversable. A query can follow a chain of connections rather than just matching vocabulary.
Microsoft Research formalized the combination of knowledge graphs and RAG in a 2024 paper introducing GraphRAG.1 GraphRAG was designed to improve performance on questions that require cross-document connection and dataset-level synthesis, two categories where standard vector similarity search often falls short because the relevant information is never contained in a single chunk. GraphRAG uses a language model to extract an entity knowledge graph from the source documents, then builds community summaries for groups of closely related entities. At query time, retrieval follows graph structure rather than vector similarity.
The Microsoft Research team conducted evaluations using metrics for comprehensiveness, meaning how completely the answer addressed the question, and diversity, meaning the range of relevant perspectives included in the answer. GraphRAG outperformed baseline RAG on both measures across multiple datasets. The improvement was not marginal. For global questions requiring synthesis across large document sets, baseline RAG frequently produced answers that were incomplete or missed the point of the question entirely. GraphRAG produced more complete, and often more useful, responses for that class of question.1
This is the same basic intuition Shannon formalized: more signal relative to noise produces better communication. AI retrieval systems are no exception. A knowledge graph is a filtering and structuring mechanism applied before retrieval. It reduces noise not by discarding data but by encoding the relationships in the data explicitly, so the retrieval step can navigate to the relevant nodes rather than pulling in everything that shares vocabulary with the query. The signal-to-noise ratio improves because the structure of the data improves, not because the model gets bigger or the context window gets longer.
For mid-market companies, the practical implication is this: if your RAG system handles simple lookups well but fails on questions that span multiple documents or require understanding how different parts of your business connect, the problem is likely architectural rather than model-related. A knowledge graph layer will do more for answer quality than any prompt engineering or model upgrade.
A Simpler Fix for a Specific Problem: Context Loss at the Chunk Level
GraphRAG addresses a structural gap in RAG: the failure to connect information across documents. But there is a different and more common failure that organizations hit earlier: a standard RAG chunk loses its context the moment it is separated from the document it came from.
The chunk problem is concrete. A chunk reading "revenue grew 3% over the prior quarter" is meaningless without knowing which company and which period. When that chunk gets embedded in isolation, the vector representation carries no information about those missing facts. At retrieval time, a question about ACME Corp's Q2 revenue may not retrieve it at all, or may retrieve it alongside many other unrelated revenue figures with similar phrasing.
In September 2024, Anthropic published a technique called Contextual Retrieval that addresses this directly.2 The approach has two components. The first, Contextual Embeddings, uses a language model to generate a short, document-specific explanation for each chunk (typically 50 to 100 tokens) and prepends that explanation to the chunk before embedding it. The second, Contextual BM25, applies the same enrichment to the keyword index. The result is that each embedded chunk carries the context it needs to be found by the right query.
Anthropic's internal testing found that Contextual Embeddings alone reduced retrieval failures by 35%. Combining Contextual Embeddings with Contextual BM25 reduced failures by 49%. Adding a reranking step on top brought the reduction to 67%.2 These are not small gains. A 67% reduction in retrieval failures means that most of the answers your system was failing to find or was finding incorrectly become available. The model is not smarter. The data it receives is cleaner.
The reason this works connects to the same principle running through both posts. A chunk that says "ACME Corp's Q2 2023 revenue grew 3% over the prior quarter, as reported in the company's 10-Q filing" is a materially different piece of data than one that says "revenue grew 3% over the prior quarter." The content is the same. The signal is not. Prepending context is a data quality intervention, not a model intervention. It adds information that was always present in the document but was being discarded by the chunking step.
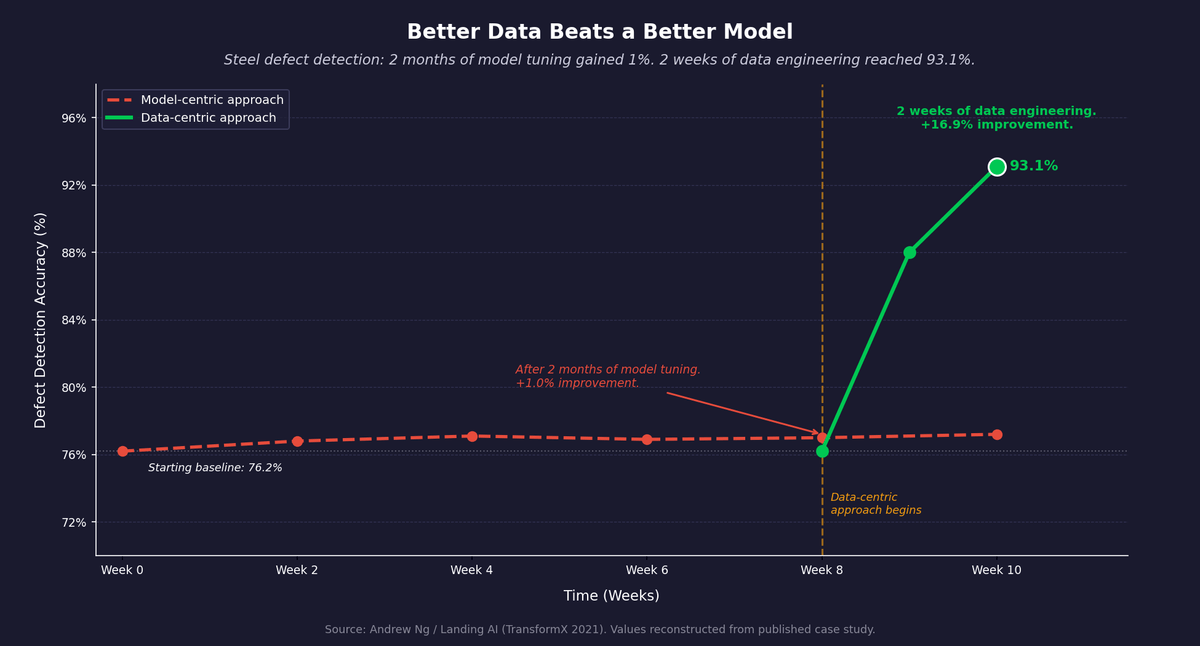
Figure 1: Steel defect detection case study. Two months of model tuning: minimal improvement. Two weeks of data engineering: accuracy from 76.2% to 93.1%. Source: Andrew Ng / Landing AI (TransformX 2021).
What This Means for Your AI Deployment
The signal-to-noise ratio in your AI system is not just a function of what data you have. It is a function of how precisely that data is filtered, ranked, and sized for the specific question being asked. Here is what to do about it.
Define the question before you define the data. Most AI data problems start with collection, not question definition. The question determines what is relevant. Before any data pipeline is designed, answer three questions: What specific decision does this system need to support? What does a correct answer look like? What does an incorrect answer cost? These answers determine what data belongs in the system and what does not.
Treat data curation as engineering work, not cleanup. The term "data-centric AI," developed by Andrew Ng at Landing AI, describes the shift from optimizing model architecture to systematically engineering data quality.3 Andrew Ng and his team have used a steel defect detection case study to illustrate the point: a steel manufacturing plant was stuck at 76.2% defect detection accuracy. Multiple teams spent two months on model-centric approaches, including hyperparameter tuning and different neural architectures, with little improvement. A data-centric approach focused on labeling consistency brought accuracy to 93.1% in two weeks.4 In many applied settings, the next unit of effort belongs in the data before it belongs in the model.
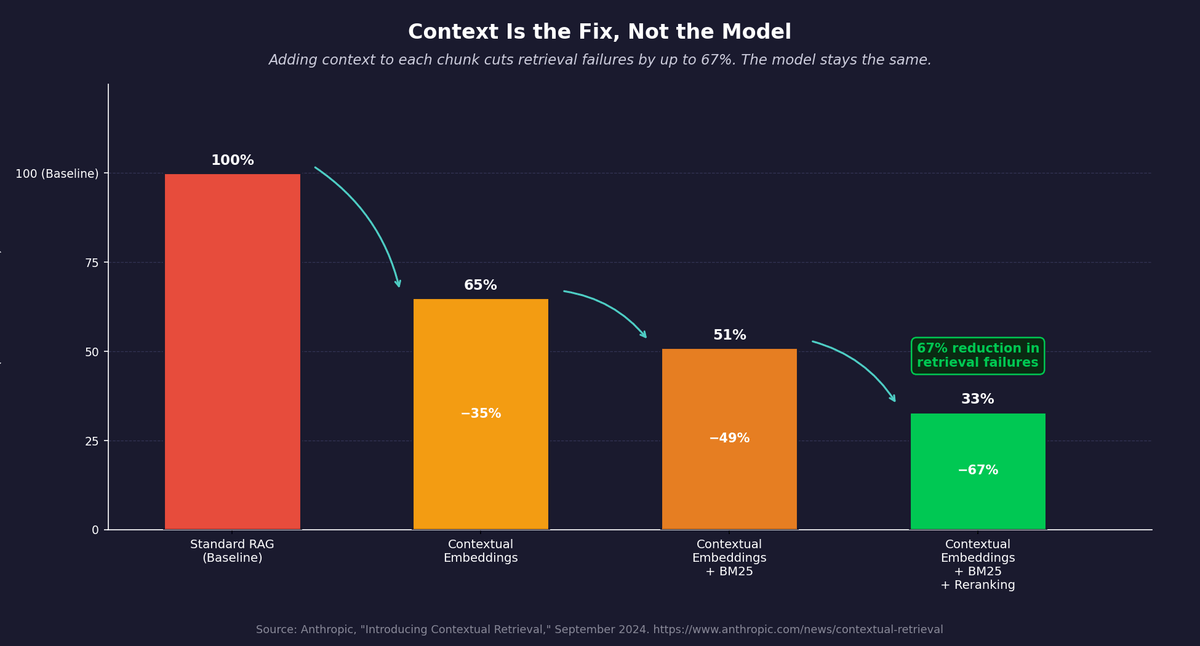
Figure 2: Contextual Retrieval reduces retrieval failures by up to 67% without changing the model. Source: Anthropic, "Introducing Contextual Retrieval," September 2024.
Build retrieval that filters, not just retrieves. For RAG systems specifically, in many business RAG settings, context precision, meaning the fraction of retrieved content that is actually relevant, matters more than maximal recall, because irrelevant context can actively degrade the answer.5 A RAG system optimized for recall at the expense of precision is actively harmful. Sophisticated implementations combine semantic vector search with keyword-based search, add reranking to re-score candidates on relevance rather than similarity, and apply context compression and sufficiency checks. These are not advanced features. They are the difference between a RAG system that works and one that confidently produces wrong answers.
Fix context loss before it reaches the model. Standard RAG strips context from chunks at indexing time. A passage that references "the company" or "this quarter" becomes unresolvable the moment it is separated from the document header. Contextual Retrieval, published by Anthropic in 2024, addresses this by prepending a short, document-specific explanation to each chunk before embedding it.2 The fix costs roughly one additional LLM call per chunk at indexing time and reduces retrieval failures by up to 67% in testing. If your RAG system is returning answers that are technically correct but about the wrong entity, the wrong time period, or the wrong context, this is the likely cause.
Consider a knowledge graph layer for complex multi-document questions. If your AI system needs to answer questions that span multiple documents, trace relationships between entities, or synthesize patterns across a dataset, standard RAG will underperform regardless of how well it is tuned. A knowledge graph pre-structures the relationships in your data so retrieval can follow entity connections rather than matching text similarity. Microsoft's GraphRAG implementation is open source and actively maintained.1 The investment is in structuring your data well enough to build the graph, which is the same investment that pays off across every other part of your AI deployment.
Set a signal-to-noise standard before deployment. Any AI system making business decisions needs a defined relevance threshold for what gets fed into it. If you cannot articulate that threshold, you do not have a data strategy. You have a data collection habit. The threshold should be specific enough to test: if a retrieved passage were shown to a knowledgeable human, would they say it is relevant to the question? If the answer is "sometimes" or "maybe," the retrieval is not precise enough.
The Competitive Advantage Is in the Filtering
Organizations frequently believe their competitive advantage in AI lies in the amount of data they possess. More transactions, more customer interactions, more historical records.
The research says otherwise. Competitive advantage comes from how well that data is structured, filtered, and prioritized for the specific questions the business needs to answer. Two companies with access to the same volume of data will produce very different AI outcomes depending on how deliberately they have engineered what goes into the model.
Shannon understood this in 1948. The companies that act on it now will spend their time getting better answers. The ones that don't will spend their time wondering why their AI keeps getting it wrong, and concluding incorrectly that the answer is more data.
Sources
- Darren Edge et al., "From Local to Global: A Graph RAG Approach to Query-Focused Summarization," Microsoft Research, arXiv:2404.16130, 2024. arXiv. ↑
- Anthropic, "Introducing Contextual Retrieval," September 2024. anthropic.com. ↑
- Andrew Ng, "Data-Centric AI," Landing AI. landing.ai. ↑
- "Google Brain's Andrew Ng says data-centric approach boosts AI success," Insight Partners, 2022. insightpartners.com. ↑
- Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press, 2008. Online edition. ↑
Frequently Asked Questions
What is GraphRAG and how does it improve AI retrieval?
GraphRAG is a technique from Microsoft Research that combines knowledge graphs with retrieval-augmented generation. Instead of retrieving text chunks by semantic similarity, it extracts entities and relationships into a knowledge graph, then follows graph structure at query time. In evaluations, GraphRAG produced more complete and diverse answers than standard RAG for questions requiring cross-document synthesis.
What is Contextual Retrieval and how much does it reduce retrieval failures?
Contextual Retrieval is a technique published by Anthropic in September 2024 that prepends a short, document-specific explanation to each text chunk before embedding it. This preserves context that standard chunking discards. Contextual Embeddings alone reduced retrieval failures by 35%. Combined with Contextual BM25, failures dropped 49%. Adding a reranking step brought the total reduction to 67%.
Why does better data matter more than a better AI model?
Research consistently shows that data quality improvements outperform model improvements. In a steel defect detection case study from Andrew Ng's Landing AI, two months of model tuning produced minimal improvement, while two weeks of data-centric work raised accuracy from 76.2% to 93.1%. The same principle applies to RAG systems: cleaning and structuring the data fed to the model produces larger gains than upgrading the model itself.
Continue Reading
The Problem with Feeding Everything to Your AI
The most expensive mistake in enterprise AI is assuming more data produces better answers. Research going back 75 years explains why it doesn't.
AI Can Write. It Cannot Think.
Writing quality and factual accuracy are independent. LLMs optimize for the first. Understanding why changes how you use every AI output.
What's Actually Inside an AI Agent (And Why Most of It Isn't AI)
Most of an AI agent isn't AI. I built one to prove it. Here's the actual breakdown and why it matters for every AI project you evaluate.
Want better answers from your AI systems?
I help companies build AI architectures that prioritize signal over volume. Let's talk.
Let's Talk