Your Engineering Team Has Most of the Right Practices. It's the Last Four That Make the Difference.

President, Zaruko
Table of Contents

Most engineering teams do sprints, code reviews, and standups. They've been doing them for years. And most of them still ship late, accumulate technical debt they can't explain, and have no clear answer for whether last quarter's work moved the business.
The practices aren't the problem. The missing ones are.
After years of evaluating software organizations from the outside, a pattern emerges. Teams that consistently deliver well don't have dramatically different rituals. They have a small number of additional practices that the average team skips, usually because they feel like overhead. They aren't. They're the practices that separate a team that compounds over time from one that runs in place.
Here are the four that matter most. These are not replacements for good product management, technical excellence, or delivery discipline. They are the missing layer that improves decision quality around all of those things.
1. Business Justification Before the Work Starts
Too much engineering work gets approved by urgency and instinct. Someone has an idea, it sounds reasonable, it goes into the backlog. A few sprints later, the team has built something that mostly works and mostly matters.
The teams that consistently build the right things require a written justification before committing to any meaningful piece of work. Not an estimate. Not a story. A short document that answers: what problem does this solve, who has the problem, what does success look like, and what is the cost of not doing it?
Writing forces decisions that conversation defers. When you have to commit your reasoning to text, the gaps in your thinking become visible. This is uncomfortable. It is also the point.
Amazon figured this out in 2004 when Jeff Bezos sent his senior team an internal email banning PowerPoint from executive meetings.1 In its place: narrative memos, written in full sentences, read in silence at the start of every meeting. Bezos's reasoning was direct. "The reason writing a good four-page memo is harder than writing a 20-page PowerPoint is because the narrative structure of a good memo forces better thought and better understanding of what's more important than what, and how things are related."1
You don't need Amazon's memo format. You need the underlying principle: written justification, before the work starts, every time.
2. Feasibility Studies for Non-Trivial Work
After you've established why something is worth building, the second skipped practice is establishing whether and how it can be built, before committing a sprint to it.
A feasibility study doesn't have to be long. Two to four pages covering the proposed design, the technical dependencies, the risks, and the open questions is enough. The goal is to surface the problems you can solve in a document rather than in production code three weeks from now.
Strong engineering teams do this before beginning any piece of work that touches a core system, introduces a new dependency, or involves meaningful architectural decisions. Average teams treat it as optional and then wonder why scope expands mid-sprint.
The cost of a feasibility study is measured in hours. The cost of skipping it is measured in weeks. A two-page feasibility study that surfaces one hidden integration dependency before a sprint starts can save three weeks of rework later.
3. Cost-Benefit Analysis for Engineering Efforts
This one gets the most resistance. Engineers and engineering managers often feel that requiring cost-benefit analysis for technical work is either bureaucratic or condescending. It is neither. It is the practice that connects engineering decisions to business outcomes.
The question is simple: what does this effort cost in time and resources, and what does the business gain if it succeeds? For features, that might be revenue or retention. For infrastructure work, it might be reliability or velocity gains. For refactoring, it might be reduced maintenance burden over the next 12 months.
You don't need exact numbers. Rough estimates, stated plainly, are far better than no estimate at all. The discipline of attempting the analysis changes how work gets prioritized. Low-ROI work, which fills most backlogs, becomes easier to defer or drop when someone has to write down what it actually delivers.
4. Post-Mortems That Actually Change Behavior
Most engineering teams run some version of a post-mortem after a significant incident. Some have good templates. Some have regular scheduling. Most of them stop at the diagnosis.
The diagnosis is not the practice. The follow-through is.
Google's Site Reliability Engineering book, which codified many of the practices now standard in software operations, is explicit on this point.3 A blameless post-mortem serves two functions: it identifies what went wrong at a systemic level, and it should produce concrete action items with clear ownership. The blameless part matters because blame produces self-protective behavior, not honest analysis. But without the action items, and without someone accountable for each one, the post-mortem is just documentation of a bad day.
The pattern in underperforming teams is consistent. Something breaks. There is a post-mortem. The post-mortem produces five action items. Two months later, three of those action items are still open, and a related incident has occurred. The lesson was documented but not absorbed.
Strong teams treat the completion rate of post-mortem action items as a signal about the health of the team's learning culture. If items consistently go unresolved, the post-mortem is theater. If they get resolved, the team is actually getting better.
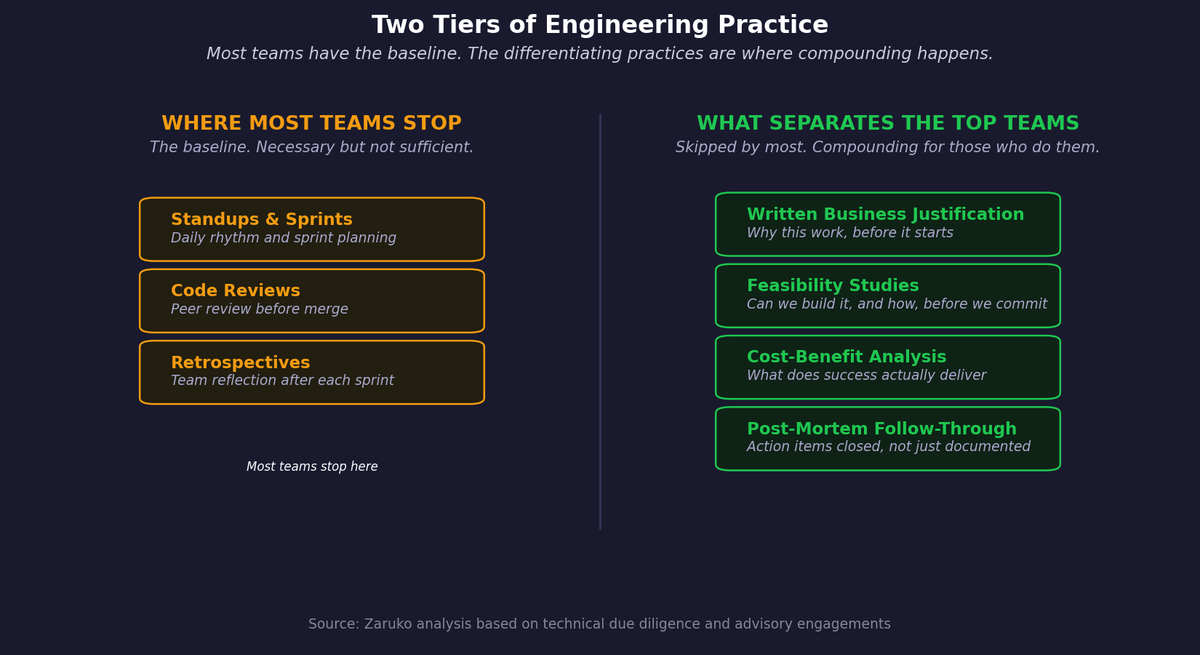
Figure 1. How common engineering practices are adopted across teams, from baseline rituals to the differentiating practices many teams skip.
The Pattern These Four Share
Business justification, feasibility studies, cost-benefit analysis, and follow-through on post-mortems all do the same thing: they slow the team down slightly before a decision, so the team moves faster after it. They operate at four different points in the work cycle: before approval, before design commitment, before resource allocation, and after failure. The underlying logic is identical.
This is not how most leaders think about these practices. The common objection is velocity. "We can't stop to write documents for everything. We need to move fast." That framing misunderstands where time actually goes. Teams don't lose time writing feasibility documents. They lose time rebuilding features that were poorly scoped, reworking architecture decisions that were made without enough analysis, and re-encountering the same production incidents because last year's post-mortem never got acted on.
The overhead is an investment. The payoff is compounding.
McKinsey's research across 440 enterprises found that top-quartile engineering organizations grow 4-5x faster than bottom-quartile peers.2 McKinsey attributes this to a broad set of factors across tooling, culture, and organizational enablement, not any single practice. That gap likely reflects better organizational decisions at every level, including sharper choices about what to build and what not to build.
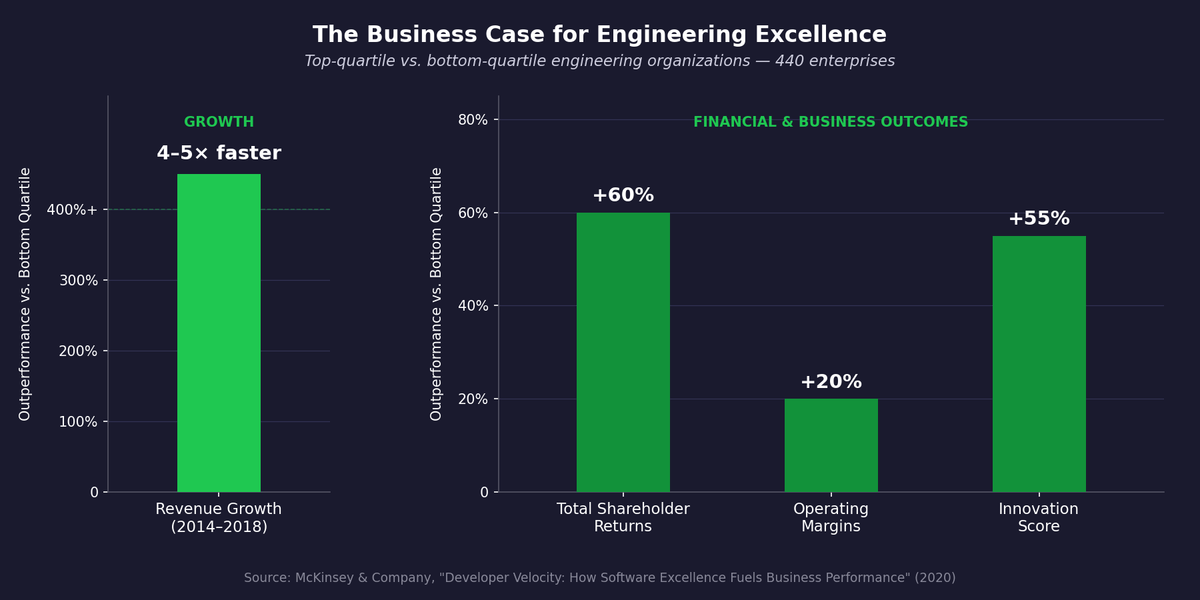
Figure 2. Business performance gap between top-quartile and bottom-quartile engineering organizations across four measures. Source: McKinsey Developer Velocity Index research, 440 enterprises.
Where to Start
You don't need to implement all four at once. Pick the one that addresses your biggest current failure mode.
If your team regularly builds things that turn out not to matter: start with business justification.
If your team regularly hits architectural surprises mid-sprint: start with feasibility studies.
If your backlog is full of work that nobody can connect to a business outcome: start with cost-benefit analysis.
If your team keeps encountering the same categories of incidents: start with post-mortem follow-through.
Any one of these, done consistently, will produce a measurable improvement in what the team ships and why. All four together describe what strong engineering teams actually do, as opposed to what they say they do.
Sources
- Jeff Bezos, "No PowerPoint Presentations from Now On at STeam" (2004 internal email), widely reported. Inc.com ↑
- McKinsey & Company, "Developer Velocity: How Software Excellence Fuels Business Performance" (2020). Survey of 440 enterprises. ↑
- Google Site Reliability Engineering, "Postmortem Culture: Learning from Failure." ↑
Frequently Asked Questions
What engineering practices separate high-performing teams from average ones?
Four decision-quality practices make the difference: (1) Written business justification before work starts, defining the problem, the user, success metrics, and the cost of inaction. (2) Feasibility studies for non-trivial work, a 2-4 page document surfacing risks and dependencies before committing a sprint. (3) Cost-benefit analysis connecting engineering effort to business outcomes. (4) Post-mortem follow-through with concrete action items, clear ownership, and tracked completion rates. These practices slow teams down slightly before decisions so they move faster after.
Why did Amazon ban PowerPoint in meetings?
In 2004, Jeff Bezos sent an internal email banning PowerPoint from executive meetings and replacing it with narrative memos read in silence. His reasoning: 'The narrative structure of a good memo forces better thought and better understanding of what's more important than what, and how things are related.' Writing forces clarity that conversation defers. The underlying principle, written justification before committing to work, is what separates teams that build the right things from teams that build whatever sounds reasonable.
How much do top engineering organizations outperform average ones?
McKinsey's Developer Velocity research across 440 enterprises found that top-quartile engineering organizations grow 4-5x faster than bottom-quartile peers. McKinsey attributes this to a broad set of factors across tooling, culture, and organizational enablement. The gap likely reflects better organizational decisions at every level: sharper choices about what to build and what not to build. Practices like business justification, feasibility studies, and cost-benefit analysis improve decision quality, which compounds over time.
Continue Reading
Your Team Structure Made Sense at 10 Engineers. It Doesn't at 40.
The structure didn't break because the people got worse. It broke because nobody redesigned it.
You're Measuring the Wrong Things. Here's What Actually Tells You If Your Engineering Team Is Healthy.
Story points and tickets closed say nothing about what's being produced. Three metrics actually predict engineering team health.
What the 5% Who Succeed with AI Actually Do Differently
MIT and BCG both found that only 5% create real value from AI. Here's what they do differently.
Want your engineering team to ship what matters?
I help mid-market companies build the decision-quality layer that separates teams that compound from teams that run in place. Let's talk.
Let's Talk