Build Once, Sell Many. AI Just Broke That.

President, Zaruko
Table of Contents

For forty years, software has been the best business model ever invented. You build something once and sell it a thousand times. The cost of serving the second customer is close to zero. The hundredth customer is nearly pure margin. That compounding logic is why mature SaaS companies run at 80 to 90 percent gross margins.1
AI is breaking that model. Not at the edges. At the foundation.
How the Old Model Actually Worked
When a company hired a software vendor ten years ago, the value exchange was simple. The client shared their business problem in enough detail for the vendor to build a solution. That information flowed into product roadmaps and engineering decisions. The vendor got paid, accumulated domain knowledge, and embedded what it learned into a product that served the next client better.
Every deployment made the vendor smarter. Every client made the software more capable. The knowledge compounded across the entire customer base. A healthcare software company that worked with fifty hospitals often understood hospital workflows more broadly than any single hospital could from its own experience alone. That accumulated insight was the moat. It was also what justified the margins.
The client shared information. The vendor turned it into capability. Both sides got value. Most clients either did not know or did not object.
Why That Exchange No Longer Works
AI requires something different as input. It does not just need a description of the business problem. It needs the data that represents the problem.
A decade ago, when machine learning startups deployed solutions, clients were largely indifferent to what happened to their operational data. They wanted the software to work. If the vendor used that data to improve the product, most clients either did not know or did not care. That is how the last generation of ML companies built their advantages. Deployment after deployment, the training data accumulated, the models improved, and the moat deepened.
That window is closed.
Enterprise clients now explicitly prohibit AI vendors from using operational or user data for model training. This is not an informal understanding. It is contract language. Debevoise and Plimpton, one of the leading law firms on enterprise AI contracts, flagged contractual data use restrictions as a significant and growing challenge for enterprise AI in 2026, noting that clients are increasingly prohibiting vendors from using their data to train AI models.2
The clause looks something like this: you may not collect, store, or use our data to train, fine-tune, or improve any AI model, yours or anyone else's. If you have worked in enterprise AI sales in the past three years, you have seen this language. It shows up in procurement templates, master service agreements, and data processing addendums. In many enterprise procurement contexts, this has shifted from a negotiating point to a baseline requirement.
The Data Has Quadfurcated
The data restriction on deployments is one part of a larger structural problem. To understand why, you need to look at what has happened to the data market itself.
For most of the last decade, the implicit assumption in AI was that data would flow. Companies would share operational data to get better software. Researchers would publish datasets. The web would remain open. That assumption is no longer operative. The data market has split into four distinct tiers, and the tiers differ sharply in how accessible they are and how much competitive advantage they create.
Data Source one: public data. The open web, public datasets, academic corpora. Free, available to everyone, and completely undifferentiated. A model trained on public data is competing against every other model trained on the same public data, including OpenAI, Google, Meta, and the major open-source projects. Public data is infrastructure. It is rarely a moat.
Data Source two: licensed datasets. These are the curated, high-quality, domain-specific datasets that would let a startup build a truly differentiated model. They now carry a price that reflects the "data is the new oil" framing that has taken hold across every industry. Stack Overflow struck a licensing deal with OpenAI for its developer knowledge base. Reddit monetized its corpus before its IPO. News publishers have sued or negotiated with every major AI company over training data rights. The data that used to flow freely into models, because nobody thought to restrict or monetize it, has been carved up and priced.
The most instructive example is OpenEvidence, an AI medical search engine used by over 40 percent of physicians in the United States, according to the company. To build a product credible enough for clinical use, OpenEvidence had to license content from the New England Journal of Medicine, the American Medical Association, JAMA and its eleven specialty publications, the National Comprehensive Cancer Network, and multiple other medical organizations.3 The company has raised nearly $700 million in funding, with significant portions of funding allocated to content licensing partnerships. The data cost is not a line item. It is a primary driver of capital requirements.
Most startups cannot raise $700 million to solve a data licensing problem.
Data Source three: purpose-built data. The only path that does not depend on someone else's permission or pricing is to create the data yourself. This means paying for human annotation, running structured data collection programs, generating synthetic data, or designing products that accumulate labeled examples as a byproduct of use. The upfront cost is high and the timeline is long. But the data is owned outright, no one can revoke it, and the cost per example typically falls over time.
The difficulty of this path is best understood by looking at who built businesses around solving it. Scale AI was founded in 2016 to help companies generate and label training data. In June 2025, Meta paid $14.3 billion for a 49 percent nonvoting stake, valuing Scale at more than $29 billion.4 Labelbox and Snorkel AI address the same problem from different angles, and both have attracted substantial institutional capital. An entire category of billion-dollar companies now exists specifically because building your own training data is hard enough and expensive enough to require specialized infrastructure. That is not a footnote to the Tier 3 path. It is the definition of it. For startups with a clear enough problem definition and enough runway, this is the most defensible path you fully control.
Data Source four: proprietary operational data. This is the data generated through the actual use of your product: transactions, workflows, user interactions, outcomes. It is the highest-value data in the market: real business activity that cannot be simulated without actually running the business. A decade ago this flowed freely into vendor models. Today it is contractually restricted by default. Clients explicitly prohibit AI vendors from collecting, storing, or using their operational data for training. As covered earlier in this post, that language is increasingly common in enterprise agreements. But this tier is not permanently inaccessible. A startup that negotiates a business deal with 2 to 5 dominant players in a vertical, offering equity, revenue sharing, or a partnership arrangement in exchange for data access, can unlock it. The data partners become aligned with the vendor's success. The contractual restriction disappears because the data owners are now on the same side. This is a high bar, but it is a real path.
The result is a market where the easiest data to get creates no competitive advantage, the most valuable data is contractually restricted by default, licensed data requires capital most startups don't have, and the only fully controllable path requires building the data from scratch.
This is not the data bifurcation that people have been discussing for years. It is something more fragmented and more damaging. I think of the market as having split into four tiers. Call it quadfurcation: four tiers of data access, each with a different level of accessibility and a different ceiling for differentiation.
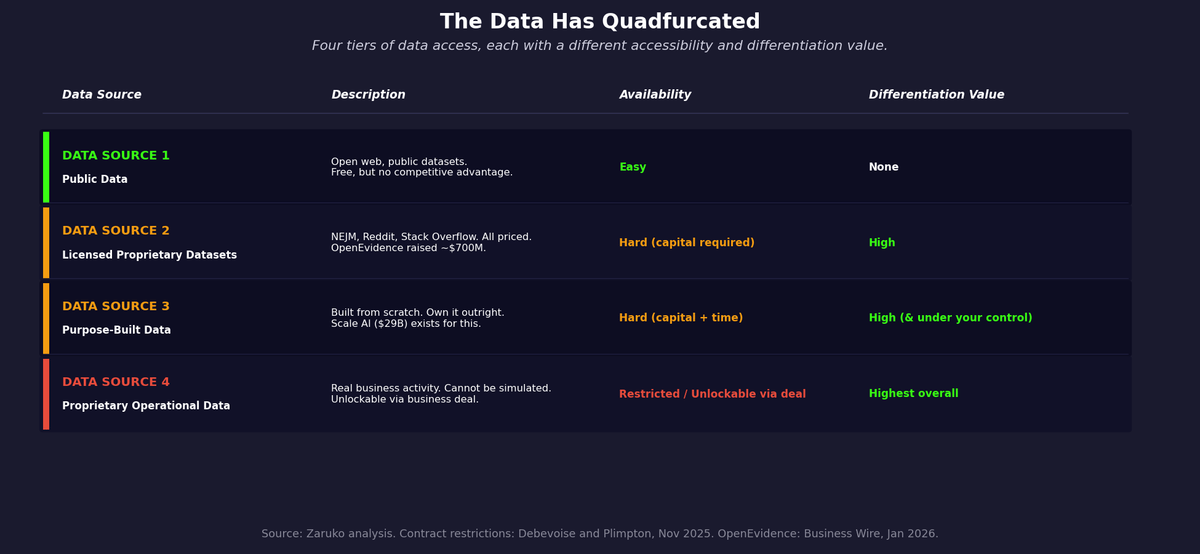
Figure 1: Four tiers of data access, mapped by accessibility and differentiation value. Sources: Zaruko analysis; Debevoise and Plimpton, Nov 2025; OpenEvidence funding announcements.
The Business Model Consequence Nobody Is Talking About
The data access problem is serious. The business model consequence is more serious. A16z observed as early as 2020 that AI companies often look more like services businesses than traditional software, pointing to lower gross margins and weaker moats.5 The contractual data restriction problem explains a structural reason why.
The software business model works because of replication. You build something for your first client. You learn from it. You take that learning and replicate it for the second client, and the third, at close to zero marginal cost. The software gets better with every deployment. The margins expand because the cost of serving each new customer is nearly zero while the revenue is not. That is the engine.
When clients prohibit AI vendors from using their data for training, they are not just restricting data access. They are breaking the replication engine.
Client A's data can make the AI solution work for Client A. But that data, and the model improvements it enables, cannot flow into the product that serves Client B. So the vendor is not building a product anymore. They are building a series of custom engagements that happen to share a codebase.
The economics start to resemble professional services more than software: more custom, more isolated, harder to scale. The replication economics are degraded, not eliminated, but degraded enough to fundamentally change the margin structure. The economics look completely different. Traditional SaaS companies run at 80 to 90 percent gross margins. Bessemer's State of AI 2025 report found that steadier-growth AI companies run around 60 percent gross margins, while the fastest-scaling cohorts average closer to 25 percent, with several running negative.6 Part of that gap is inference cost. Part of it is this: each client engagement is more isolated, more custom, and less able to benefit from what the vendor learned elsewhere. There are exceptions: vendors who negotiate explicit training rights, build segregated fine-tuning pipelines, or use federated approaches that improve models without accessing raw data. But these exceptions require legal sophistication and technical investment that most early-stage companies have not budgeted for.
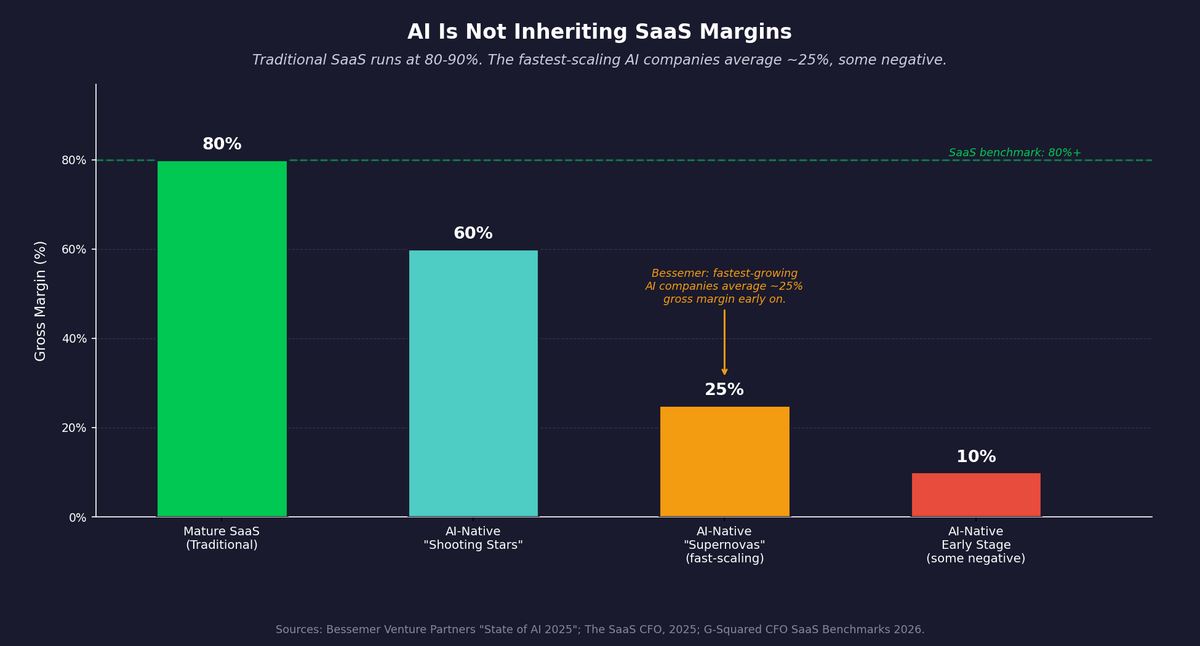
Figure 2: Traditional SaaS gross margins run 80-90%. AI-native companies average 50-60%, with the fastest-scaling cohorts reported closer to 25% or negative. Sources: Bessemer Venture Partners, February 2026; The SaaS CFO, 2025.
What the Software Industry Has Not Faced Before
There is a deeper problem embedded in this shift that goes beyond margin compression.
Software companies became valuable because accumulated knowledge compounds. Every client engagement makes the next one better. The product improves continuously. The vendor's ability to serve any given client keeps increasing even without that client's involvement. That compounding is what turns a software company into something durable.
AI vendors cannot compound the same way if they cannot learn from deployment. Vendors still carry over workflows, evaluation frameworks, and engineering patterns from one engagement to the next. But the model itself, the thing that gets better as it sees more data, stays siloed inside each client's walls. The model improvement that would have flowed across clients does not.
This changes the innovation trajectory for the entire application layer. Foundation model providers keep improving because they have the scale, resources, and, in some cases, the right to learn from usage at scale. The companies building specific applications for specific industries, the ones solving the actual business problems, are losing the feedback loop that would make their solutions better over time.
Where This Ends Up
The honest answer is that nobody knows exactly how this resolves. There are several possible outcomes, none of them fully satisfying. The most likely scenario is not that one of them wins, but that all of them play out simultaneously across different industries, verticals, and problem types.
Outcome 1: Every Software Deployment Becomes a Custom Engagement
One is a world of highly customized AI solutions, where each deployment is built around a specific client's data and cannot generalize beyond that client. The software economics collapse into something closer to managed services. More custom, more fragmented, lower margins, harder to scale.
Outcome 2: Foundation Model Providers Build the Application Layer Themselves
A second is that foundation model providers move upstream and build applications directly. A16z argued in March 2026 that this pressure will not kill application software: moats from workflow integration, network effects, and process knowledge persist regardless of model commoditization.7 That may well be right for companies with deep vertical workflow embedded in their customers' operations. The question is narrower: what happens to vendors who built on thinner foundations, and what happens to the replication engine when deployment data cannot flow back to the vendor. OpenAI has done this with ChatGPT and its operator integrations. Anthropic has done it with Claude Code and enterprise Claude products. Google has done it across Workspace. This is not the model providers making specialized vendors irrelevant by raw capability alone. It is the model providers competing directly in the application layer they once left to startups. The space available to general-purpose AI wrappers compresses. Startups that built deep vertical workflow in specific domains, the Harvey and Cursor model, remain defensible. Startups that built thin interfaces on top of general-purpose models face the most direct pressure.
Outcome 3: New Data Sharing Structures Emerge
Another is that new data sharing structures emerge: consortiums, data trusts, synthetic data approaches, or privacy-preserving techniques like federated learning that let vendors improve models without accessing raw client data. Some of this is happening, but slowly and unevenly.
Outcome 4: Traditional Software Makes a Partial Comeback
There is a fourth outcome that gets less attention but may be the most interesting: traditional software makes a partial comeback, built faster with AI as a construction tool rather than a runtime component. In this scenario, AI writes the code but does not run it. No client data is used to build the software: just requirements, logic, and domain knowledge, the same inputs that went into software construction before LLMs existed. The resulting software is conventional, does not require ongoing model access, and processes the client's data without any model needing to see it at inference time. The data restriction problem disappears because there is nothing to restrict. The replication economics return because the marginal cost of deploying the same software to the next client approaches zero. This is the old business model, built at a fraction of the old cost. It will not work for every problem. Some business problems are too unstructured or domain-specific to be solved without training on real data. But for a meaningful class of well-defined problems, it is a viable path. It is possible that the very constraints driving clients to lock down their data end up accelerating it.
Outcome 5: The Two-Phase Product Model
A fifth outcome may be the most commercially promising: vendors build the base product on public and licensed data, sell it to many customers with full SaaS replication economics, and then let the product improve within each customer's environment using their own data, without that data ever leaving their walls or flowing back to the vendor. Phase one is the traditional software model: build once, sell many times, marginal cost approaches zero. Phase two is customer-specific improvement that happens architecturally inside the customer's environment rather than contractually at the vendor's discretion. The vendor never asks for training rights because they do not need them. The customer gets a product that gets better over time. Neither side has to negotiate an exception to the data restriction clause because the architecture makes the restriction irrelevant. This path requires deliberate product design from the start: the base model has to be useful enough to sell, and the fine-tuning pipeline has to work within the customer's own environment without vendor access. But for vendors who build it correctly, it preserves both the replication economics of software and the compounding improvement of AI.
Of these five outcomes, four describe how the market may evolve around you. The fifth is different. The two-phase product model is something you can design for today, without waiting for regulatory change, new data structures, or foundation model behavior to shift. For startups building now, it is the path most within your control.
There is an important technical caveat. Most AI software vendors today are not architected for this path. The standard enterprise AI deployment model separates training, which happens internally at the vendor, from inference, which runs in the customer's environment. The model is static once deployed. It does not learn from what it sees in production. Deloitte estimated that inference workloads already accounted for half of all AI compute in 2025, and will reach two-thirds by 2026.8 That infrastructure is built around a one-way flow: train centrally, serve at the edge. Reversing that architecture to allow in-customer fine-tuning without vendor access requires deliberate design from the start, and most teams have not built it that way.
Two additional clarifications on what the two-phase model actually requires. First, the initial model does not have to be trained on public data. It can be trained on any data the vendor has legitimately acquired: licensed datasets, purpose-built annotation, synthetic data, or prior deployments where training rights were negotiated. In some cases, it can start with no training data at all: a minimal base model that begins converging on the customer's operational data after deployment, generating inference results only after it has accumulated enough signal to be reliable. Second, the mechanism for in-customer improvement is technically well-established. Federated fine-tuning, where a model adapts to local data without that data leaving the customer's environment, is already used in healthcare, finance, and other data-sensitive industries to customize foundation models on proprietary data without exposing it to any external party.9 The pattern is technically feasible and increasingly deployed in data-sensitive industries. What most AI software vendors lack is the product architecture and go-to-market discipline to build around it from day one.
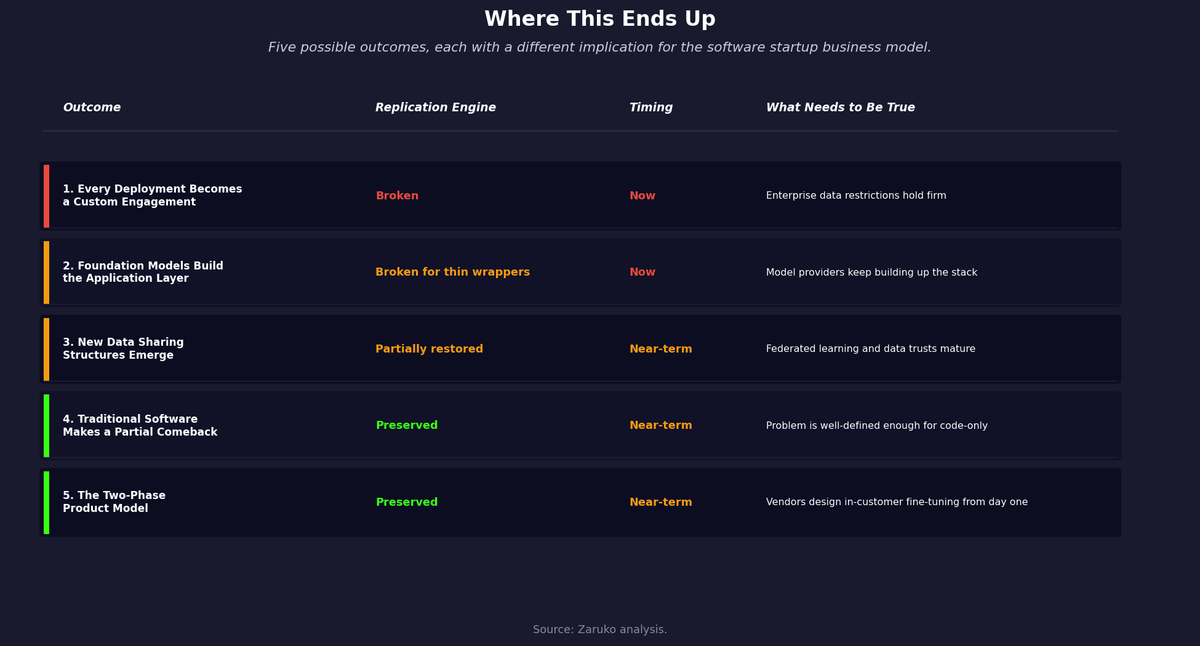
Figure 3: Five possible outcomes mapped by their impact on the software replication engine and timing. Source: Zaruko analysis.
What is clear is that the assumptions built into most AI startup business plans, that deployment data will compound into a moat, that the software replication model will work the way it always has, do not hold under the contractual conditions that enterprise clients are now imposing.
The moment is not stable. The AI startup ecosystem is operating on business model assumptions that the legal and procurement teams of their own clients are already invalidating. Most founders have not priced this in. Most investors have not either.
Sources
- Bessemer Venture Partners, "The AI Pricing and Monetization Playbook," February 2026. bvp.com. ↑
- Debevoise and Plimpton, "AI's Biggest Enterprise Challenge in 2026: Contractual Use Limitations on Data," November 2025. debevoisedatablog.com. ↑
- OpenEvidence Series D announcement, Business Wire, January 2026. businesswire.com. ↑
- Reuters, "Meta to pay $14.3 billion for 49% stake in Scale AI," June 2025. reuters.com. ↑
- Martin Casado and Matt Bornstein, "The New Business of AI (and How It's Different from Traditional Software)," Andreessen Horowitz, February 2020. a16z.com. ↑
- Bessemer Venture Partners, "State of AI 2025," August 2025. Referenced in Tanay Jaipuria, "The State of AI Gross Margins in 2025," September 2025. tanayj.com. ↑
- Alex Immerman and Santiago Rodriguez, "Good news: AI Will Eat Application Software," Andreessen Horowitz, March 2026. a16z.com. ↑
- Deloitte, cited in "CES 2026: AI compute sees a shift from training to inference," Computerworld, January 2026. computerworld.com. ↑
- Google Cloud, "What is federated learning?" cloud.google.com. ↑
Frequently Asked Questions
Why are AI company margins lower than SaaS margins?
Traditional SaaS companies run at 80-90% gross margins because the cost of serving each additional customer is close to zero. AI companies average 25-60% gross margins because of two factors: inference compute costs and the breakdown of the replication engine. Enterprise clients now contractually prohibit AI vendors from using deployment data to train or improve models, which means each client engagement is more isolated and custom. The vendor cannot take what it learned from Client A and replicate it for Client B, pushing the economics closer to professional services than software.
What is the data quadfurcation in AI?
The AI data market has split into four tiers with different levels of accessibility and competitive advantage. Tier 1 is public data (free but undifferentiated). Tier 2 is licensed datasets (high-quality but expensive, for example OpenEvidence raised nearly $700M partly to fund clinical data licensing). Tier 3 is purpose-built data (you create it yourself through annotation, synthetic generation, or product usage, for example Scale AI's $29B valuation shows how hard this is). Tier 4 is proprietary operational data (the highest-value data, now contractually restricted by default in enterprise agreements).
How can AI startups preserve software replication economics?
The most actionable path is the two-phase product model: build the base product on public and licensed data with full SaaS replication economics, then let the product improve within each customer's environment using their own data, without that data ever leaving their walls. The vendor never asks for training rights because the architecture makes data restrictions irrelevant. This requires deliberate product design from day one, including federated fine-tuning pipelines, but it preserves both the replication economics of software and the compounding improvement of AI.
Continue Reading
The Unbundling of LLMs
LLM wrappers get dismissed. But the companies building real workflow around foundation models are following the same pattern that created billion-dollar SaaS companies.
74% Want Revenue from AI. 20% Are Getting It.
88% of companies have adopted AI. Fewer than 40% can point to a financial result. The gap between AI winners and everyone else is widening fast.
Better Data Beats More Data. Here's How to Build for It.
Knowledge graphs, contextual retrieval, and data-centric AI deliver larger gains than model upgrades.
Navigating the AI business model shift?
I help mid-market companies understand where AI creates durable value and where the economics don't hold. Let's talk.
Let's Talk