AI Orchestration Without Visibility Creates Hidden Bottlenecks

President, Zaruko
Table of Contents

The first three posts in this series made the optimistic case. AI agents are bringing point solutions back. The orchestration layer makes multiple agents work together. The infrastructure layer gives you choices about where agents run and how they access data. The market data supports all three claims.
Now the reality check.
Most orchestration efforts focus on the "happy path." They answer the question: "When everything works, how do tasks flow between agents?" That is necessary but insufficient. The harder question, and the one most organizations are not asking, is: "When something breaks, who absorbs the impact?"
The "Happy Path" Problem
A well-designed orchestration layer makes multi-agent workflows look smooth from the top. Dashboards show task completion rates, throughput, and average processing time. Leadership sees green indicators. The system appears to be working.
But orchestration dashboards measure what the system produces. They rarely measure what happens to the exceptions, the edge cases, and the errors that fall outside the automated path. Those land on a human somewhere downstream, and that human is almost always invisible to the people reading the dashboards.
This is not a theoretical concern. It is the oldest problem in process automation, and AI agents are making it worse because they process at a volume and speed that amplifies the exception volume even when the exception percentage stays low.
Consider a practical example. An AI agent processes 2,000 invoices per day with a 97% accuracy rate. That sounds excellent. But 3% of 2,000 is 60 invoices per day that land on a human for manual review. Before the agent, a team of five people processed 400 invoices per day with a 95% accuracy rate, handling the 20 daily exceptions as part of their normal workflow. After deployment, the agent pushes 60 exceptions per day to the same downstream queue. The agent quintupled throughput and improved accuracy by two percentage points. The dashboard looks great. But the person handling exceptions just went from 20 per day to 60 per day, and nobody adjusted their workload, their tools, or their staffing to account for it.
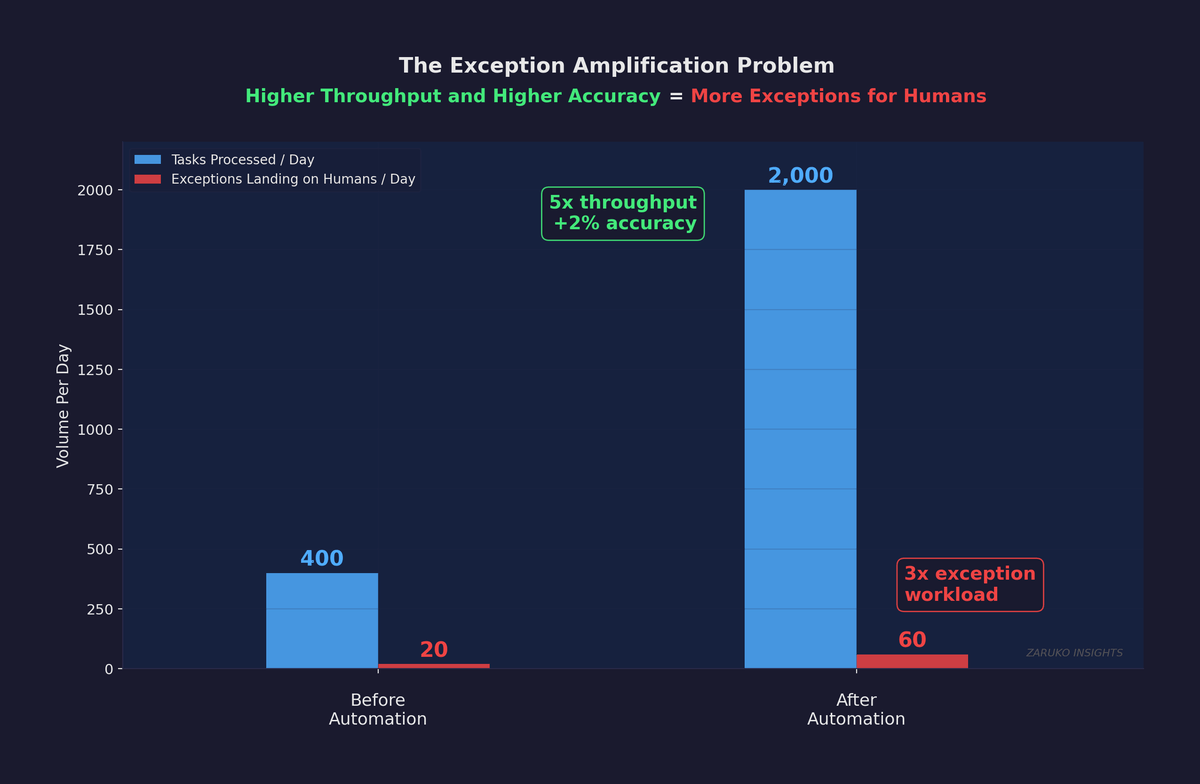
The Exception Amplification Problem: higher throughput and higher accuracy still means more exceptions for humans.
Where Friction Actually Accumulates
The problem compounds across multi-agent chains. When Agent A passes an error to Agent B, Agent B may not recognize it as an error. It processes the bad input and passes a subtly wrong output to Agent C. By the time a human catches the problem, the reconciliation breaks, the compliance queue grows, and the root cause is buried three systems upstream.
The people who absorb the most friction in these systems share three characteristics. They sit at the boundaries between automated and manual processes. They handle the work that agents could not complete. And they are almost always measured on their own output, not on the upstream failures that create their workload.
This is the visibility problem. The orchestration layer sees agents completing tasks. It does not see humans cleaning up after agents. And because those humans are in different departments, on different teams, with different managers, nobody has a system-level view of where friction actually accumulates.
Gene Kim summarizes this in DevOps systems thinking: never allow local optimization to create global degradation, and always seek to achieve a profound understanding of the system.1 That principle applies directly to AI agent orchestration. The orchestration layer is a local optimization if it only measures agent performance. It becomes a system-level tool only when it also measures the human work that agent failures generate.
What Real Visibility Looks Like
There is a fundamental difference between traditional software and AI agents that makes this visibility problem harder than it first appears. In traditional software, you can read the code to understand what the application does. With AI agents, you cannot. Agents are non-deterministic. The same input can produce different outputs depending on context, memory, and the model's reasoning at that moment. In practice, the most reliable way to understand what an agent actually did, and why, is to read the trace: the complete record of every action, every decision, every context handoff.
This means that agent traces are not just a debugging tool. They are the documentation of your business process. If you cannot trace the full path from the initial trigger through every agent action to the final outcome, you do not understand your own workflow. And if the trace stops at the boundary where automated work becomes human work, you have a blind spot exactly where the most important information lives.
The monitoring and observability function we described in The Orchestration Layer needs to extend beyond agent telemetry. It needs to track three additional things.
Exception flow
Where do exceptions exit the automated path, and where do they land? Every time an agent hands a task to a human, that handoff should be logged with the same detail as an agent-to-agent handoff. Volume, frequency, type of exception, and time to resolution.
Error propagation
When an error originates in one agent and is discovered downstream, the system should trace back to the source. This requires the context passing infrastructure from The Orchestration Layer to include confidence signals and validation checkpoints, not just task data.
Human absorption rates
How many exception tasks is each human team handling, and how is that volume trending? If your AP team's exception workload has tripled since you deployed an invoice processing agent, that is not a success story. It is a capacity mismatch hiding behind an automation success metric.2
The organizations that do this well measure total system friction, not just automated throughput. They ask not only "how many tasks did the agents complete?" but also "what happened to the tasks the agents could not complete, and who is dealing with them?"
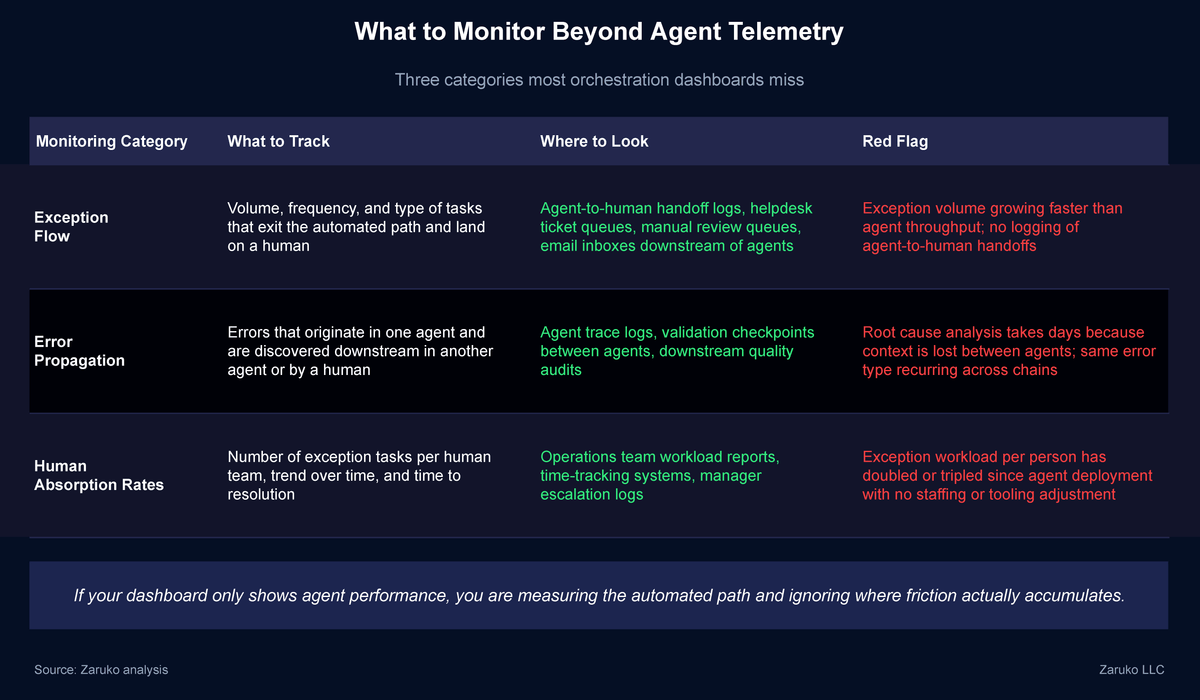
What to Monitor Beyond Agent Telemetry: three categories most orchestration dashboards miss.
The Leadership Blind Spot
This creates a specific problem for leadership. The orchestration layer, by design, makes everything look smooth from the top. That is what it is supposed to do. But if the monitoring only covers the automated path, leadership loses visibility into the human cost of automation.
The people absorbing the most friction are often the least visible to the executives making investment decisions about AI agents. They are the operations analysts reviewing flagged transactions. The compliance officers checking edge cases. The customer service representatives handling the tickets that the AI could not resolve. Their workload is a direct function of how well the agents perform, but their metrics are rarely connected to agent performance dashboards.
This is not a technology problem. It is an organizational design problem that technology makes worse if you do not account for it. The fix is simple but requires intentional effort: connect the exception handling metrics to the agent performance metrics so that leadership sees the full picture, not just the automated slice.
What To Do About It
Run the exception math on one agent. Take your highest-volume agent, multiply daily volume by error rate, and compare that number to what the downstream team was handling before deployment. If the number tripled and nobody adjusted staffing or tooling, you have found your first bottleneck.
Log agent-to-human handoffs the same way you log agent-to-agent handoffs. If your orchestration layer tracks when Agent A passes work to Agent B, it should also track when Agent A passes work to a human. Same detail: volume, frequency, type, and time to resolution.
Add exception volume to the agent performance dashboard. Put it next to throughput and accuracy so leadership sees both numbers in the same view. An agent that processes 2,000 tasks and generates 60 exceptions tells a different story than one that just processes 2,000 tasks.
Ask the people downstream. Before your next agent deployment review, talk to the teams handling exceptions. They already know where the friction is. They have been living with it since the agent launched.
The Bottom Line
Orchestration without visibility into where friction accumulates is not orchestration. It is optimism with a dashboard.
The organizations that succeed with multi-agent systems will be the ones that measure the full workflow, automated and manual, and use that visibility to identify where agents are creating problems, not just where they are solving them.3
- Gene Kim, The Phoenix Project and "The Three Ways: The Principles Underpinning DevOps." The principle of never allowing local optimization to create global degradation applies directly to AI agent orchestration. ↑
- Deloitte, "Unlocking Exponential Value with AI Agent Orchestration," November 2025. Projection that advanced organizations will shift to human-on-the-loop orchestration in 2026 requires the visibility infrastructure described in this post. ↑
- CIO.com, "Taming Agent Sprawl: 3 Pillars of AI Orchestration," February 2026. Orchestration efficiency metric (successful tasks / total compute cost) should be expanded to include exception handling cost. ↑
Frequently Asked Questions
What is the exception amplification problem in AI automation?
When AI agents process at high volume, even low error rates create large absolute numbers of exceptions that land on humans. For example, an AI agent processing 2,000 invoices per day at 97% accuracy generates 60 exceptions daily. Before the agent, a human team processing 400 invoices at 95% accuracy only handled 20 exceptions. The agent improved both throughput and accuracy, but tripled the human exception workload. Dashboards show the improvement; they hide the downstream impact.
What should you monitor beyond AI agent performance dashboards?
Three things most dashboards miss: (1) Exception flow: where do tasks exit the automated path and land on a human, tracked with the same detail as agent-to-agent handoffs. (2) Error propagation: when an error originates in one agent and surfaces downstream, trace it back to the source. (3) Human absorption rates: how many exception tasks each human team handles and how that volume is trending over time.
Why do AI orchestration dashboards create a leadership blind spot?
Orchestration dashboards measure what agents produce: task completion rates, throughput, and processing time. They rarely measure what happens to the exceptions. The people absorbing the most friction (operations analysts, compliance officers, customer service reps) sit in different departments with different managers. Nobody has a system-level view of where friction accumulates, so leadership sees green indicators while downstream teams are overwhelmed.
Continue Reading
The Orchestration Layer: What It Is, What It Does, and What to Look For
The five core functions every orchestration layer must perform.
AI Agents Are Bringing Back Point Solutions. This Time, It Might Actually Work.
AI agents are reversing the logic that drove platform consolidation. Here's why point solutions are back.
Where Your AI Agents Actually Run: Compute, Data, and Infrastructure Decisions
The infrastructure decisions you make now will shape cost, security, and vendor dependency for years.
Seeing hidden bottlenecks in your AI workflows?
I help mid-market companies design AI orchestration that measures the full workflow, both automated and manual. Let's talk.
Let's Talk