Where Your AI Agents Actually Run: Compute, Data, and Infrastructure Decisions

President, Zaruko
Table of Contents

In our last post, we defined the five functions of the orchestration layer and introduced the Zaruko Framework for evaluating them. But we left an important question unanswered: where do these agents actually run?
An orchestration layer coordinates agents. But agents need compute to execute, data to reason over, and an execution environment to operate in. Those infrastructure decisions will shape your cost structure, your security posture, your compliance obligations, and your vendor dependencies for years. And most organizations are making them without a clear framework for thinking about the trade-offs.
The Infrastructure Layer Nobody Talks About
The AI agent conversation is dominated by capabilities. What can agents do? How do they collaborate? What orchestration patterns work best? Those are important questions, and we covered them in the previous post.
But capabilities run on infrastructure. Every agent needs three things to function: compute resources to execute its reasoning, access to the data it needs to make decisions, and a runtime environment that connects it to the tools and systems it acts on. The choices you make about each of these will constrain or enable everything else in your agent strategy.
This is not a theoretical concern. The AI agent market itself is projected to grow from $7.8 billion in 2025 to over $52 billion by 2030, a 46% compound annual growth rate.1 The infrastructure those agents run on is growing even faster. Data center spending is projected to jump 31.7% in 2026 to exceed $650 billion, driven heavily by AI-related infrastructure demand.2 The five largest US cloud and AI infrastructure companies alone plan to spend between $660 billion and $690 billion on capital expenditure in 2026, up from approximately $380 billion in 2025.3 That spending is building the infrastructure that your agents will run on. The question is whether you are making deliberate choices about which infrastructure, or letting your vendors make those choices for you.
Three Platform Models
Those needs (compute, data, and runtime) get delivered through one of three operating models. Each has real trade-offs that go beyond the usual cloud-versus-on-prem debate.

Three platform models for running AI agents, compared across speed, control, and operational burden.
Vendor-managed agent platforms. Salesforce Agentforce, Microsoft Copilot Studio, ServiceNow AI Agents, and similar offerings provide the full stack: compute, runtime, data connections, and orchestration bundled together. You configure agents within the platform. The vendor handles the infrastructure. This is the fastest path to deployment and the lowest operational burden. The trade-off is that your agents are tightly coupled to the vendor's environment. If your best accounts payable agent comes from a different vendor, the platform may not support it well, or at all. Gartner predicts that 40% of enterprise applications will include task-specific AI agents by the end of 2026, up from less than 5% in 2025.4 Most of those will be vendor-managed, running inside the application platform itself.
Cloud-hosted self-managed. You deploy agents on AWS, Azure, or GCP using open-source frameworks like LangGraph, CrewAI, or AutoGen, or using the cloud provider's agent services (AWS Bedrock Agents, Azure AI Foundry, Google Vertex AI Agent Builder). You control the architecture, the framework choices, and the orchestration logic. The cloud provider supplies the compute and the model APIs. This model gives you more flexibility than vendor-managed platforms but requires engineering investment to build, deploy, and maintain. Cloud infrastructure services reached $102.6 billion in Q3 2025, with a 25% year-over-year increase, reflecting the scale of enterprise investment in this approach.5
On-premises / self-hosted. You run agents on your own hardware, in a colocation facility, or on infrastructure you fully control. This is distinct from cloud self-managed, where you deploy on a public cloud provider's infrastructure. Here, you own or lease the physical compute. This model provides maximum control over data, compute, and operations. It is also the most operationally demanding. You manage the GPUs, the model serving infrastructure, the runtime environments, and the scaling. For most mid-market companies, full on-premises deployment is impractical for anything beyond lightweight agents running small models. But for specific workloads, the on-premises option is becoming more viable as model sizes decrease and inference-focused hardware improves. IBM, Microsoft, and HPE all launched sovereign and private AI infrastructure offerings in the past year specifically to address this demand.6
The practical reality is hybrid. Most organizations will end up running agents across all three models. Salesforce agents inside Salesforce. Custom agents on cloud infrastructure. Sensitive workloads on private infrastructure. This is not speculation. Seventy percent of enterprises already use hybrid cloud strategies combining at least one public and one private cloud, and a Barclays CIO survey found that 86% of CIOs plan to move at least some workloads from public cloud back to private or on-premises infrastructure.7 The reasons are cost, compliance, and control, and AI agents are accelerating all three. The orchestration layer from our previous post is what holds this together and it needs to work across all three environments.
The Data Problem Is Harder Than the Compute Problem
Compute is a purchasing decision. Data access is an architecture problem.
Every agent needs data to reason over. An AP agent needs invoice data, vendor records, contract terms, and historical payment patterns. A customer service agent needs customer profiles, order history, support ticket context, and product documentation. A workforce planning agent needs headcount data, attrition trends, compensation benchmarks, and hiring pipeline status.
That data lives in dozens of systems: your ERP, your CRM, your HRIS, your data warehouse, your document repositories, your email archives. It is stored in different formats, governed by different policies, owned by different teams, and updated at different frequencies.
The question is not whether agents can access data. The question is how they access it, and what happens when they do.
The data readiness gap is the single biggest barrier to agent deployment at scale. Fewer than 20% of organizations report having mature data readiness for AI, and over 80% lack the infrastructure to govern agent access to enterprise data.8 A 2026 survey of over 500 data leaders found that 80% rank a semantic layer with standardized definitions as the most important enabler of AI, above AI tools themselves and above faster processing.9 The implication is clear: you can buy all the compute you want, but if your data is not agent-ready, your agents will fail.
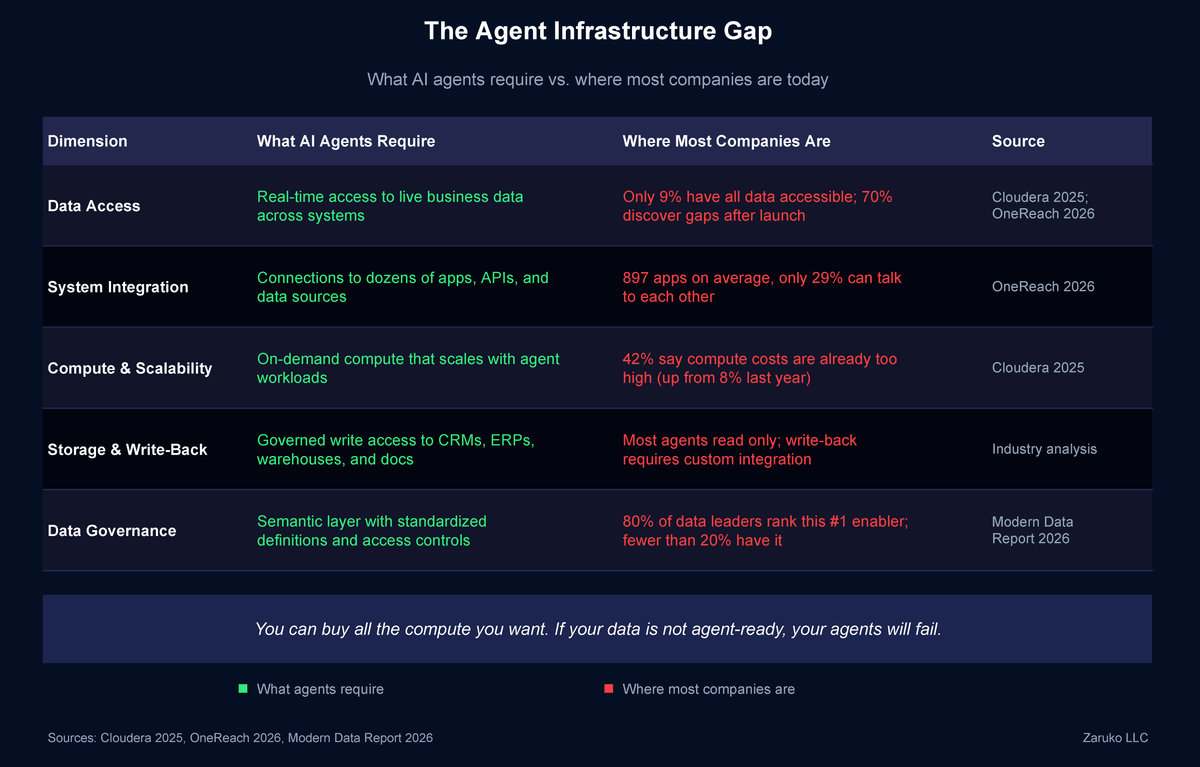
What AI agents require versus where most companies are today across five infrastructure dimensions.
There are three patterns emerging for how agents connect to enterprise data.
Direct tool connections via MCP. Anthropic's Model Context Protocol, which we covered in The Orchestration Layer, is emerging as a leading standard for how agents connect to tools and data sources. An agent uses MCP to query a database, call an API, read a document store, or interact with an application. The advantage is real-time access to live data. The risk is that every connection is a potential security exposure point, and every agent needs carefully scoped permissions for what data it can access and what actions it can take.
Retrieval and grounding via data layers. Instead of giving agents direct access to source systems, you build a data layer that curates, governs, and serves data to agents. Microsoft's architecture guidance recommends grounding agents on "Silver-layer" data that retains raw relationships and structure rather than pre-aggregated analytics data.10 Informatica, Cloudera, and other data platform vendors are building unified data access layers specifically for agent workloads, with pre-built connectors, governance rules, and access controls built in.11 This approach adds latency and complexity, but it provides a single point of control for data governance.
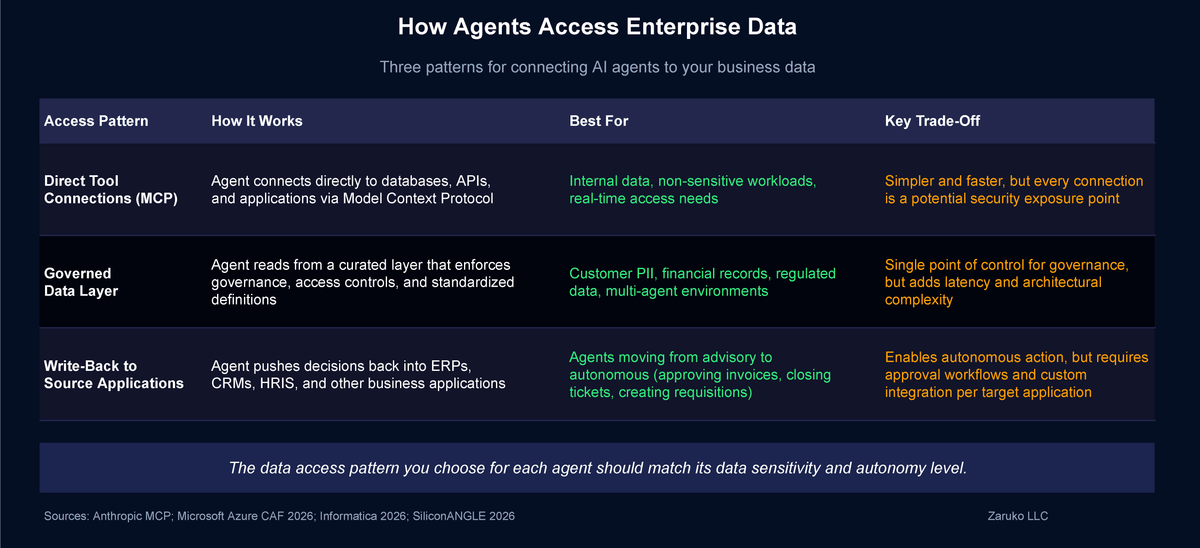
Three patterns for connecting AI agents to your business data.
Write-back to source applications. There is a third dimension beyond reading and reasoning: agents also need to write. An AP agent that approves an invoice needs to update the ERP. A customer service agent that resolves a ticket needs to close it in the CRM and log the resolution. A workforce planning agent that identifies a staffing gap needs to create a requisition in the HRIS. Today, most enterprise agents are read-only by default. They can pull data and generate recommendations, but writing back to source systems requires custom API integration for each target application. As agents move from advisory to autonomous, storage and write-back architecture becomes a core infrastructure requirement, not an afterthought. This includes where agents store their own working memory and intermediate results (vector databases, caches, session stores), where they persist their outputs for audit and compliance, and how they push decisions back into the applications your teams use every day. We will cover agent storage architecture in more detail in a future post.
The organizations getting this right are treating data infrastructure as a first-class architectural concern for AI agents, not bolting agent access onto their existing data pipelines as an afterthought. As one industry analysis put it: the enterprise data stack was not designed for continuous, autonomous AI. The challenge is no longer storing and organizing information. It is delivering that data, consistently and in real time, to systems that reason and act without pause.12
What This Means for Your Agent Strategy
The infrastructure layer is where your orchestration strategy becomes real. The five functions from the Zaruko Framework in The Orchestration Layer (task routing, context passing, workflow management, monitoring, governance) all depend on infrastructure choices you make at this layer.
Three questions to answer before you deploy
Where will your agents run, and why? Map each agent to a platform model (vendor-managed, cloud self-managed, or on-premises/self-hosted) based on its data sensitivity, performance requirements, and integration needs. Do not default to a single model for everything.
A practical starting point: use vendor-managed platforms for agents that operate within a single application, cloud self-managed for agents that need to work across multiple systems, and on-premises only for workloads with strict regulatory or data residency requirements.
How will your agents access data? Decide whether each agent connects directly to source systems or goes through a governed data layer. The answer may be different for different agents.
If an agent touches only internal, non-sensitive data, direct MCP connections are simpler and faster. If it processes customer PII, financial records, or regulated data, route it through a governed data layer with strict access controls.
What are your compliance constraints? Know which data is regulated, which agents process it, and whether your infrastructure choices support the compliance requirements you face today and the ones coming in the next two years.
If you cannot answer this question for a specific agent, do not deploy it until you can.
These are not IT decisions. They are business decisions with IT implications. The CEO and CFO need to be part of these conversations because the choices affect cost structure, risk exposure, vendor dependency, and regulatory compliance.
The Bottom Line
AI agents do not float in the cloud. They run on specific compute, access specific data, and operate within specific regulatory boundaries. The infrastructure decisions you make now will shape what your agents can do, how much they cost, and whether they create compliance risk.
Our previous post on the orchestration layer defined what it does. This post defines where it runs and what it connects to. In our next post, we will shift from the solutions side to the reality check: what happens when orchestration dashboards show everything working but the people downstream tell a different story.
Sources
- MarketsandMarkets, AI Agents Market Report, 2025. Market projected to grow from $7.84B in 2025 to $52.62B by 2030, a 46.3% CAGR. marketsandmarkets.com ↑
- Gartner, worldwide IT spending forecast, February 2026. Data center systems spending projected to jump 31.7% in 2026 to exceed $650 billion. gartner.com ↑
- Futurum Group, "AI Capex 2026: The $690B Infrastructure Sprint," February 2026. Aggregate 2026 capex plans for Microsoft, Alphabet, Amazon, Meta, and Oracle. futurumgroup.com ↑
- Gartner, "40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026," August 2025. gartner.com ↑
- Omdia, cloud infrastructure services spending report, Q3 2025. Cloud infrastructure services reached $102.6B, up 25% year-over-year. omdia.tech.informa.com ↑
- IBM Sovereign Core announcement, January 2026; Microsoft Sovereign Cloud announcement, February 2026; HPE sovereign-by-design infrastructure, February 2026. newsroom.ibm.com ↑
- Flexera, 2025 State of the Cloud Report. 70% of respondents use hybrid cloud strategies; Barclays CIO Survey Q4 2024, 86% of CIOs planned to move some workloads back to private cloud or on-premises. flexera.com ↑
- Index.dev, "AI Agent Enterprise Adoption Statistics," 2025. Fewer than 20% report mature data readiness; over 80% lack mature AI infrastructure. index.dev ↑
- Modern Data Report 2026, survey of 540+ data leaders and practitioners. 80% rank semantic layer with standardized definitions as most important AI enabler. moderndata101.substack.com ↑
- Microsoft, "Data Architecture for AI Agents," Azure Cloud Adoption Framework, 2026. learn.microsoft.com ↑
- Informatica, "Enterprise AI Agent Engineering and Data Infrastructure," 2026; Cloudera, "2026 Predictions," January 2026. informatica.com; cloudera.com ↑
- SiliconANGLE / theCUBE Research, "Vast Reshapes Data Infrastructure for Agentic AI," February 2026. siliconangle.com ↑
Frequently Asked Questions
What infrastructure do AI agents need to run in production?
Every AI agent needs three things to function: compute resources to execute its reasoning, access to the data it needs to make decisions, and a runtime environment that connects it to the tools and systems it acts on. These get delivered through vendor-managed platforms, cloud-hosted self-managed infrastructure, or on-premises deployment. Most organizations end up running agents across all three models.
What are the three platform models for running AI agents?
The three models are: vendor-managed platforms (like Salesforce Agentforce or Microsoft Copilot Studio) that bundle the full stack for fast deployment but limit flexibility; cloud-hosted self-managed (deploying on AWS, Azure, or GCP with open-source frameworks) for more architectural control at higher engineering cost; and on-premises self-hosted for maximum data control with the highest operational burden. Most organizations will use a hybrid of all three.
Why is data access harder than compute for AI agents?
Compute is a purchasing decision. Data access is an architecture problem. Agent data lives in dozens of systems in different formats, governed by different policies, owned by different teams. Fewer than 20% of organizations report mature data readiness for AI, and over 80% lack the infrastructure to govern agent access to enterprise data. You can buy all the compute you want, but if your data is not agent-ready, your agents will fail.
Continue Reading
The Orchestration Layer: What It Is, What It Does, and What to Look For
The orchestration layer makes multiple AI agents work together. Here are the five core functions, what to look for, and how to evaluate solutions.
AI Agents Are Bringing Back Point Solutions
AI agents are reversing the logic that drove platform consolidation. Here's why point solutions are back.
What's Actually Inside an AI Agent (And Why Most of It Isn't AI)
Most of an AI agent isn't AI. I built one to prove it. Here's the actual breakdown.
Making infrastructure decisions for AI agents?
I help mid-market companies make the compute, data, and infrastructure choices that determine whether AI agents deliver value or create risk. Let's talk.
Let's Talk