Before You Bet 90 Days on AI: An Operator's Scoping Checklist

President, Zaruko
Table of Contents

I posted two days ago about an AI-generated market analysis that fell apart under basic fact-checking, and why the root cause is architectural: language models optimize for fluent writing, not factual accuracy.
The response that got the most traction was a question about what happens on the buyer side. If you are evaluating AI for your own operations, how do you scope a project that does not end up in the 42% of initiatives that S&P Global found companies are abandoning?1
Most AI projects do not fail because the model was weak. They fail because the project was scoped like a technology rollout instead of a controlled process experiment.
Here is the framework I use with every company I advise.
Start With the Process, Not the Technology
Most failed AI projects start with the technology. Someone sees a demo, gets excited, and tries to figure out where to apply it. This is backwards.
Start with pain. Find the workflow where people are spending the most time on the lowest-value work. The intake step that takes three people four hours a week. The reconciliation process that someone dreads every month. The review cycle that adds five days to every approval.
Then ask one question: can you explain this current process clearly enough that a new hire could execute it tomorrow?
If you cannot, it is not ready for automation. It is ready for a process mapping exercise. AI does not fix broken processes. It automates them, which makes them break faster.
I worked with a company that automated their vendor onboarding workflow before anyone realized there were three different versions of the process running across regional offices. The AI faithfully replicated whichever version it was trained on, which meant two-thirds of the regions got outputs that contradicted their own procedures. They spent more time fixing the automated output than the manual process ever took.
Scope for the Smallest Useful Test
You are not trying to "implement AI across operations." You are testing whether one painful step can be automated safely.
The right scope has four characteristics. It involves one step in one process owned by one team with one measurable outcome. If your scope description includes the word "and" more than once, it is too big.
A good 90-day bet sounds like: "Automate the first-pass review of vendor invoices against PO terms, reducing manual review time by 50% without increasing error rates."
A bad 90-day bet sounds like: "Use AI to transform our procurement workflow and improve vendor relationships."
The first one is testable. The second one is a strategy deck.
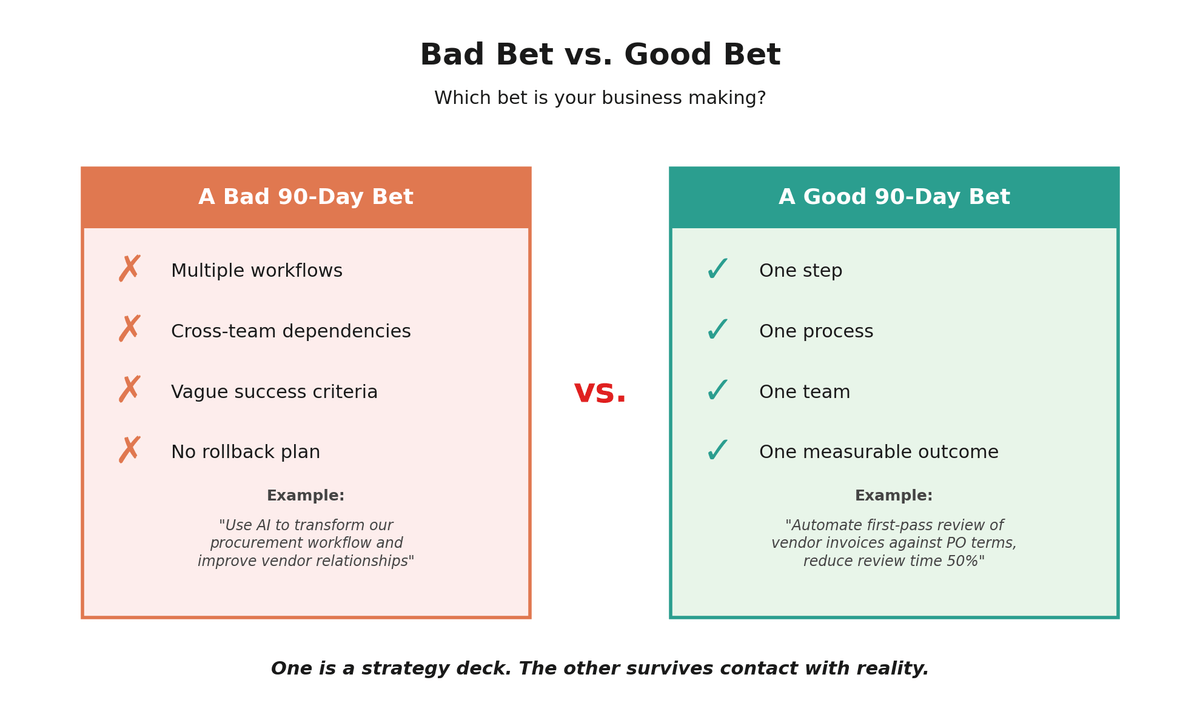
A testable scope has one step, one process, one team, and one measurable outcome.
The Scoping Checklist Beyond Metrics
Every team thinks about what to measure. Almost no one thinks about what happens when things go wrong. Beyond metrics, here is what most teams miss in scoping.
Ownership of errors. When the AI gets it wrong, who owns the output? Not who built the model. Who faces the customer or signs the document. If you cannot name this person before you start, you are not ready to start.
Handoff definition. Where exactly does the automated step end and the human step begin? Vague handoffs are where failures hide. "The AI drafts it and then someone reviews it" is not a handoff definition. "The AI drafts the response, flags items below an agreed confidence threshold for manual review, and the customer success lead approves all outbound messages" is a handoff definition.
Rollback plan. If you kill this on day 45, what happens? If the answer is "we cannot go back," your 90-day bet is actually a permanent commitment. You need to be able to revert to the manual process within 24 hours at any point during the test.
Kill authority. One person with explicit authority to stop the project. Not a committee. Not a quarterly review. One person who can pull the plug the moment something breaks.
Data boundaries. What data leaves your environment, where does it go, and who else can see it. Think customer PII, contracts, pricing data, internal communications. This is not a compliance checkbox. This is a question your customers will eventually ask, and you need a specific answer.
The go-live test. Something breaks after launch. Who gets the call and what do they do in the first 15 minutes? If you do not have a specific answer, you have not finished scoping.

If you cannot answer all six, you have not finished scoping.
How to Know if the Bet Worked
The right question is not just "did the metric improve?" It is "did it improve without creating problems we did not anticipate?"
At minimum, you should be tracking four things: your primary target metric (time saved, cost reduced, throughput increased), the error or rework rate on automated outputs, one downstream metric that the automated step feeds into (customer satisfaction, churn, escalation volume), and the override rate, meaning how often humans reject or manually correct what the AI produces. If that override rate is climbing, your automation is not working regardless of what the primary metric says.
I have seen teams automate outbound customer responses, hit their time-reduction target, and then discover three months later that churn increased because tone drifted in ways no metric caught. The dashboard looked great. The customers were leaving.
At the end of 90 days, I ask five questions. Did the target metric improve? Did any adjacent metrics get worse? Did the people downstream of the automated step report new problems? Did the error rate stay within the tolerance we defined at the start? Would the team choose to keep this running if the decision were entirely theirs?
That last question matters more than the numbers. If the people closest to the process do not trust the output, the metric improvement is temporary. They will build workarounds, and within six months you will have a manual process running in parallel with an automated one, which is worse than either alone.
The Bigger Picture
The S&P Global abandonment data is not about bad technology. It is about bad scoping. Companies that treat AI projects like technology implementations fail. Companies that treat them like process experiments with clear boundaries, defined ownership, and honest evaluation criteria learn fast and compound their wins.
The model is rarely the constraint. Discipline is. The companies that win with AI are not chasing the newest capability. They are the ones that treat every deployment like a controlled experiment with clear boundaries, defined accountability, and the willingness to shut it down.
Metrics tell you if something worked. Guardrails and handoffs determine whether you survive when it doesn't.
Sources
- S&P Global Market Intelligence, "2025 Enterprise AI Survey," survey of over 1,000 enterprises. 42% of respondents reported abandoning most AI initiatives, up from 17% in 2024. ciodive.com ↑
Frequently Asked Questions
How should companies scope their first AI project?
Scope for the smallest useful test: one step in one process owned by one team with one measurable outcome. If your scope description includes the word 'and' more than once, it is too big. A good 90-day bet sounds like 'Automate first-pass review of vendor invoices against PO terms, reducing manual review time by 50%.' A bad one sounds like 'Use AI to transform our procurement workflow and improve vendor relationships.'
Why do most enterprise AI projects fail?
Most AI projects fail because they are scoped like technology rollouts instead of controlled process experiments. Companies see a demo, get excited, and try to figure out where to apply it, which is backwards. The S&P Global 2025 survey found 42% of companies abandoned most AI initiatives, up from 17% in 2024. The constraint is rarely the model. It is discipline: clear boundaries, defined ownership, and honest evaluation criteria.
What should you check before deploying AI in business operations?
Six things beyond metrics: (1) Error ownership: who faces the customer when AI gets it wrong, (2) Handoff definition: where exactly automation ends and human judgment begins, (3) Rollback plan: can you revert to manual within 24 hours, (4) Kill authority: one person who can stop the project immediately, (5) Data boundaries: what data leaves your environment and who sees it, (6) Go-live test: who gets the call when something breaks and what happens in the first 15 minutes.
Continue Reading
First Principles of AI
Ten foundational principles for evaluating AI claims and making better decisions.
What's Actually Inside an AI Agent (And Why Most of It Isn't AI)
I built an AI agent to prove that most of it isn't AI. Here's the actual breakdown.
Your AI Pilot Worked. That's the Worst Thing That Could Have Happened.
88% of AI proofs-of-concept never reach production. The problem isn't the technology.
Planning an AI pilot?
I help mid-market companies scope AI projects that produce measurable results instead of expensive lessons. Let's talk about your 90-day bet.
Let's Talk